SHA-256 is mathematically sound — but that doesn't make your passwords safe. How the algorithm works, where...
How SHA-256 works: Can you decrypt it?
SHA-256 is mathematically sound — but that doesn't make your passwords safe. How the algorithm works, where implementations fail, and what correct password storage actually looks like.
AES-256 has no practical weakness — classical or quantum. The real risk is everything around it: key management, access...
What is AES-256 encryption: Is it truly unbreakable in 2026?
AES-256 has no practical weakness — classical or quantum. The real risk is everything around it: key management, access control, and credential hygiene. Here's what actually gets organizations breached, and what to fix first.
Every time you connect to a Wi-Fi network, send a message through an encrypted app, or access your bank account online,...
Guide to Advanced Encryption Standard (AES)
Every time you connect to a Wi-Fi network, send a message through an encrypted app, or access your bank account online, you're relying on encryption to keep your data safe. At the heart of this digital security infrastructure stands the Advanced Encryption Standard (AES) — the encryption algorithm...
Introduction
Data breaches have become routine: millions of users worldwide face the consequences of compromised...
Private password breach checking: A new algorithm for secure password validation
Introduction
Data breaches have become routine: millions of users worldwide face the consequences of compromised passwords. The scale is staggering: billions of credentials are exposed, fueling automated attacks and credential stuffing on a massive scale. Services like "Have I Been Pwned" now...
Symmetric encryption is the workhorse of modern data security. AES-256 protects everything from database records to TLS...
Pros and cons of symmetric algorithms: Ensuring security and efficiency
Symmetric encryption is the workhorse of modern data security. AES-256 protects everything from database records to TLS sessions, and it does so faster than any alternative at scale. The cipher itself is not the problem. The problem is the key — who holds it, how it's stored, and what happens when...
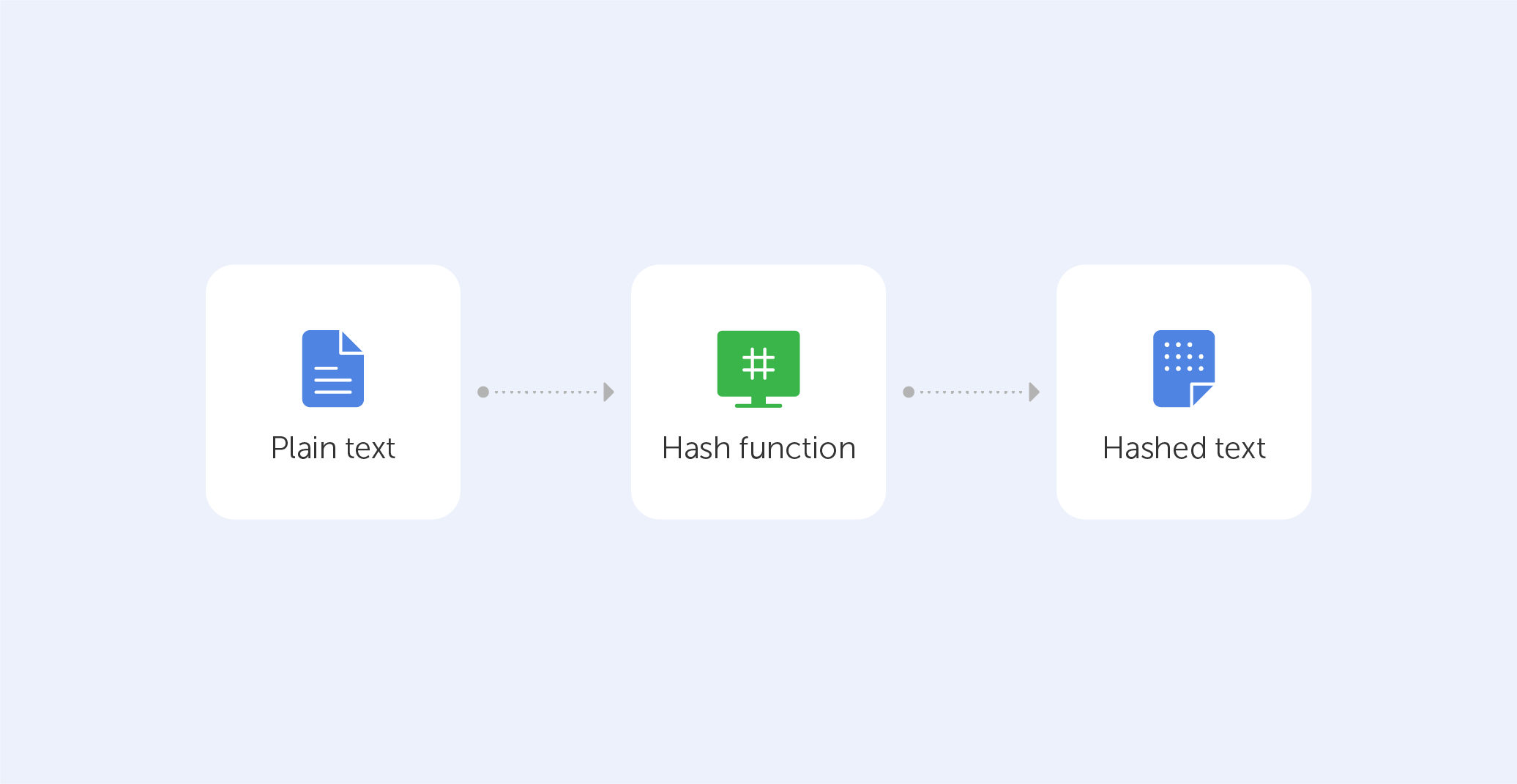
If you've heard of ‘SHA’ in various forms but aren't sure what it stands for or why it's essential — you’re in luck!...
How SHA-256 works
If you've heard of ‘SHA’ in various forms but aren't sure what it stands for or why it's essential — you’re in luck! We'll attempt to shed some light on the family of cryptographic hash algorithms today.
But, before we get into SHA, let's go over what a hash function is and how it works. Before...
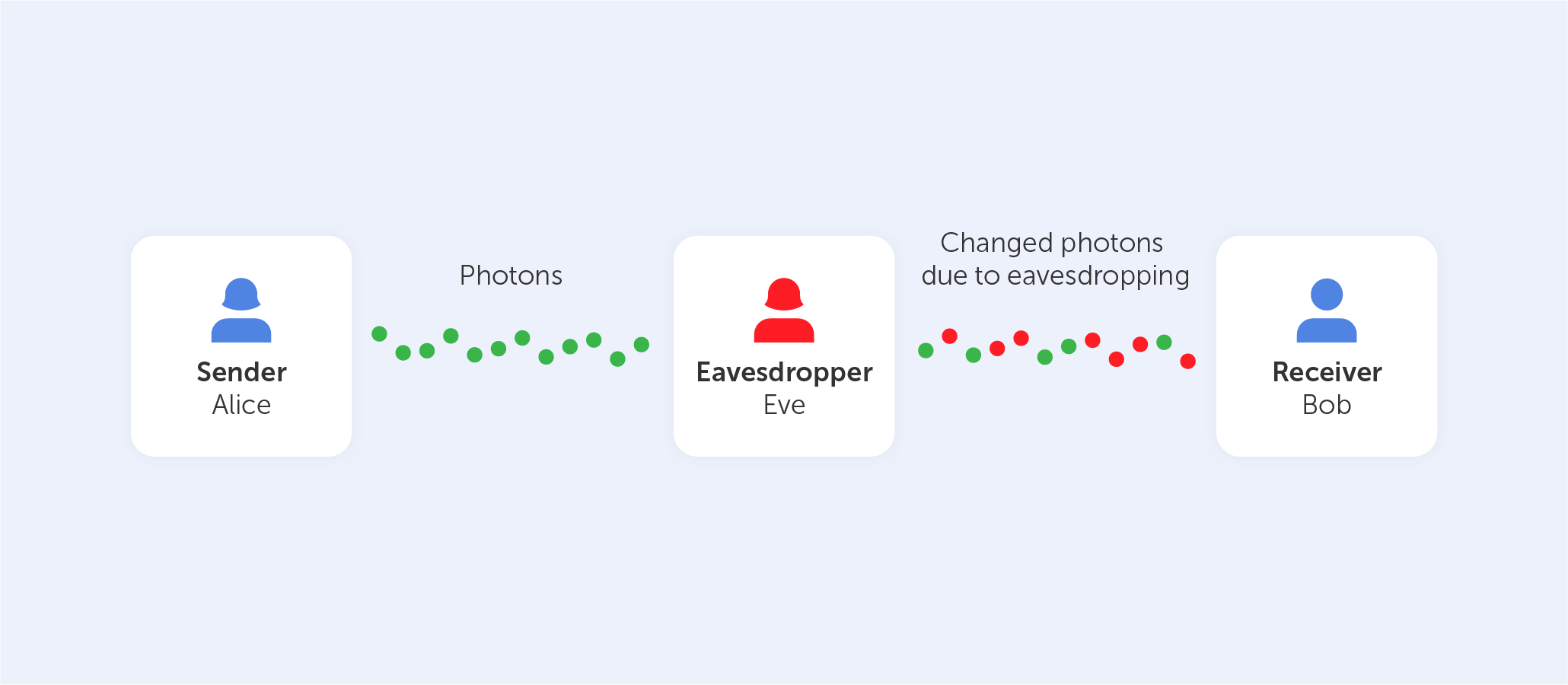
If the concept of ‘quantum cryptography' sounds complicated to you, you're right. That’s why this ‘encryption tutorial...
What is quantum cryptography?
If the concept of ‘quantum cryptography' sounds complicated to you, you're right. That’s why this ‘encryption tutorial for dummies’ shall demystify the concept and provide an explanation in layman’s terms.
Quantum cryptography, which has been around for a few decades, is becoming more and more...
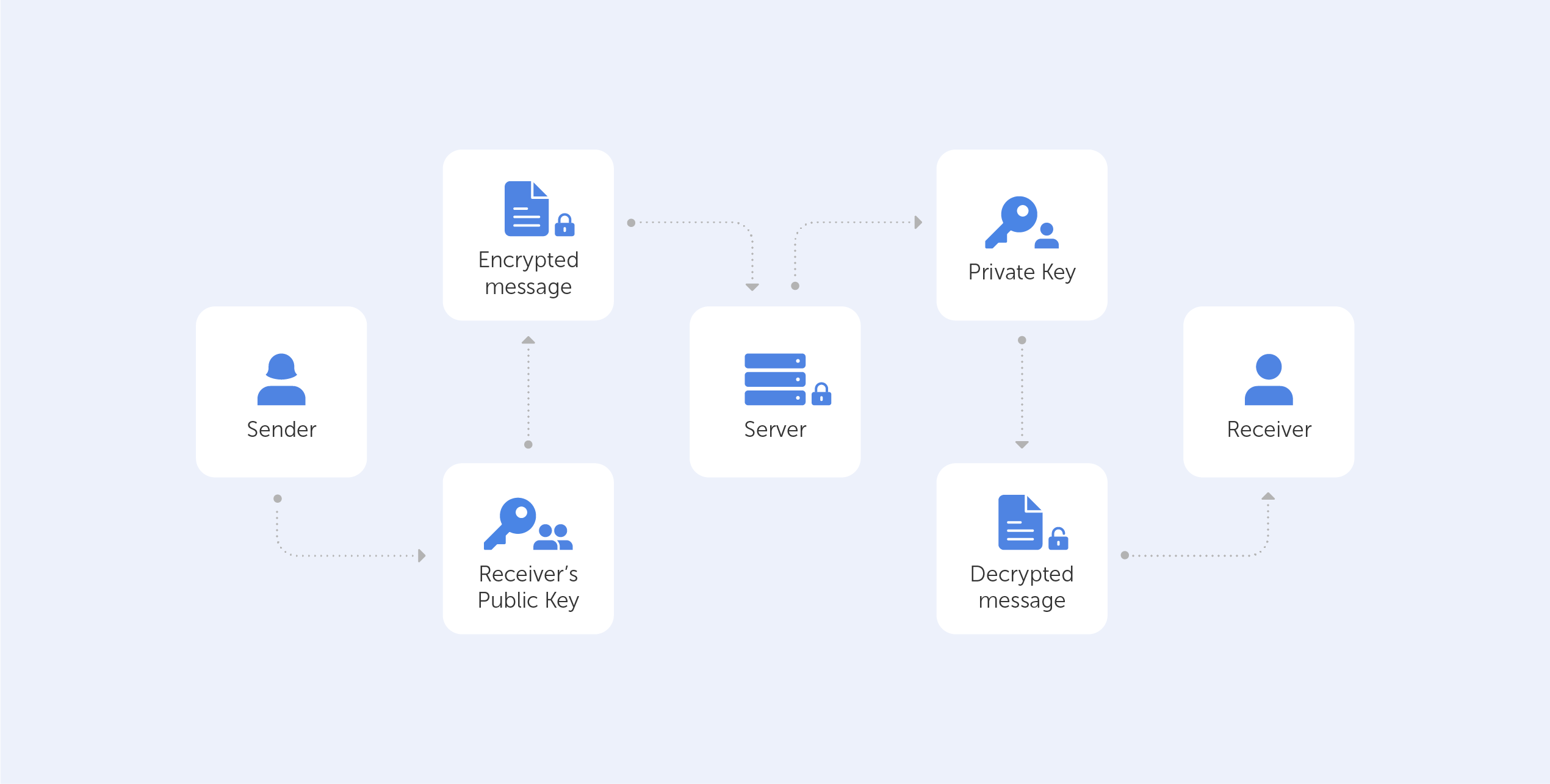
End-to-end encryption has been introduced by many communication providers in recent years, notably WhatsApp and Zoom....
What is End-to-end encryption?
End-to-end encryption has been introduced by many communication providers in recent years, notably WhatsApp and Zoom. Although those companies have tried to explain the concept to their user base several times, we believe they failed. Whilst it's clear that these platforms have increased security,...
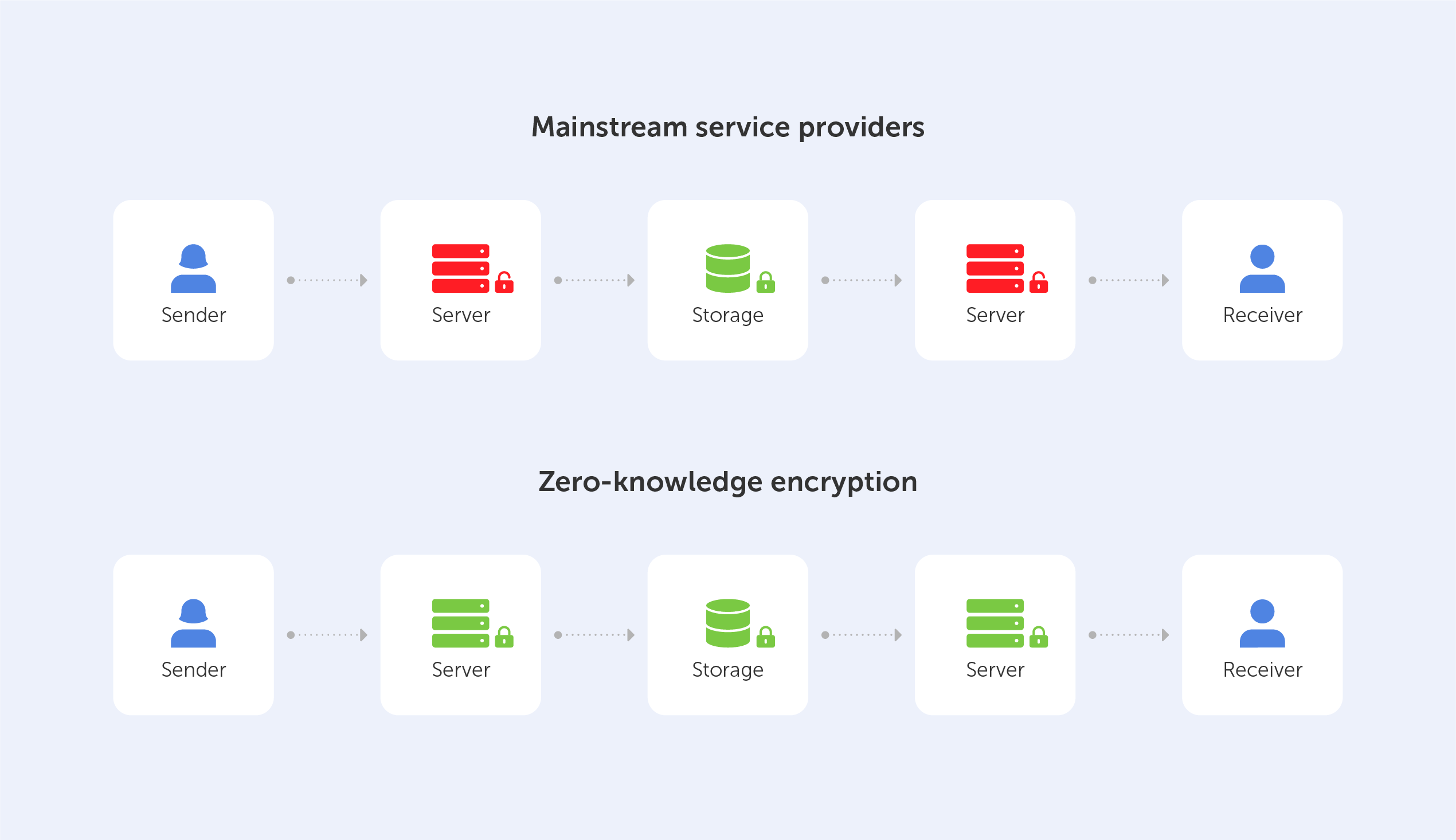
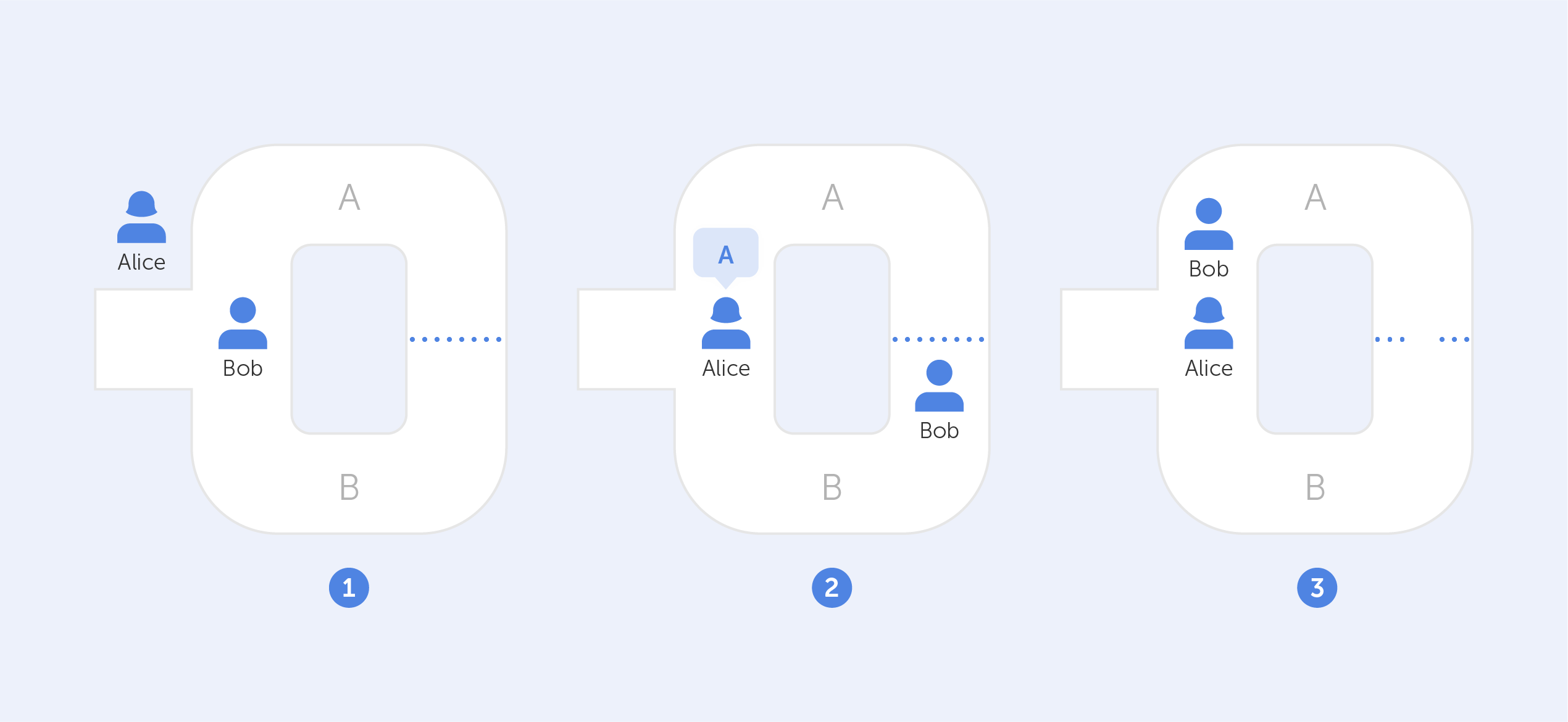
In this year of our lord, 2022, the term ‘Zero-Knowledge Encryption’ equates to best-in-class data insurance. We’ve...
Why Zero-Knowledge Encryption is the best
In this year of our lord, 2022, the term ‘Zero-Knowledge Encryption’ equates to best-in-class data insurance. We’ve already written an article named “What is Zero-Knowledge Proof?”, so we’re not going to look at definitions here, but rather, we’re going to explore the pros and cons of...
It is rare for technologies to be born from ambitious philosophical concepts or mind games. But, when it comes to...
What is Zero-knowledge proof?
It is rare for technologies to be born from ambitious philosophical concepts or mind games. But, when it comes to security and cryptography – everything is a riddle.
One of such riddles is ‘How can you prove that you know a secret without giving it away?’. Or in other words, ‘how can you tell...