It is rare for technologies to be born from ambitious philosophical concepts or mind games. But, when it comes to security and cryptography – everything is a riddle.
One of such riddles is ‘How can you prove that you know a secret without giving it away?’. Or in other words, ‘how can you tell someone you love them without saying that you love them?’.
The Zero-Knowledge Proof technique, as suggested by the name, uses cryptographic algorithms to allow several parties to verify the authenticity of a piece of information without having to share the material that makes it up. But how is it possible to prove something without supporting evidence? In this article, we’ll try our best to break it down for you as easily as possible.
Why?
We’re asking ourselves day after day – why on Earth would people decide to use such a complicated concept. Well, millions of people use the internet every day, accepting cookies and sharing personal information in exchange for access to services and digital products. Users are gradually becoming more vulnerable to security breaches and unauthorized access to their data. Furthermore, individuals frequently have to give up their privacy in return for digital platform services such as suggestions, consultations, tailored support, and so on, all of which wouldn’t be available when browsing privately. Due to all the above mentioned, there is a certain asymmetry regarding access to information – you give your information in exchange for a service.
In 1985, three great minds noticed ‘a great disturbance in the Force’ ahead of their time and released a paper called "The Knowledge Complexity of Interactive Proof-Systems" which introduced the concept of Zero-Knowledge Proof (ZKP) for the first time.
So what is it?
ZKP is a set of tools that allows an item of data to be evaluated without having to reveal the data that supports it. This is made feasible by a set of cryptographic methods that allow a "tester" to mathematically prove to a "verifier" that a computational statement is valid without disclosing any data.
It is possible to establish that particular facts are correct without having to share them with a third party in this way. For example, a user could demonstrate that he is of legal age to access a product or service without having to reveal his exact age. Or, it’s a bit like showing your friend your driving license instead of proving to him that you can drive by road-tripping to Mexico.
This technique is often used in the digital world to authenticate systems without the risk of information being stolen. Indeed, it’s no longer necessary to provide any personal data in order to establish a person's identity.
Sounds great, but how does it work?
The prover and the verifier are the two most important roles in zero-knowledge proofs. The prover must demonstrate that they are aware of the secret whereas the verifier must be able to determine whether or not the prover is lying.
It works because the verifier asks the prover to do actions that can only be done if the prover is certain that he or she is aware of the secret. If the prover is guessing, the verifier's tests will catch him or her out. If the secret is known, the prover will pass the verifier's exam with flying colours every time. It's similar to when a bank or other institution requests letters from a known secret word in order to authenticate your identity. You're not telling the bank how much money you have in your account; you're simply demonstrating that you know.
Wonderful, but how does it REALLY work?
To answer this, let’s take a look at a piece of research by Kamil Kulesza.
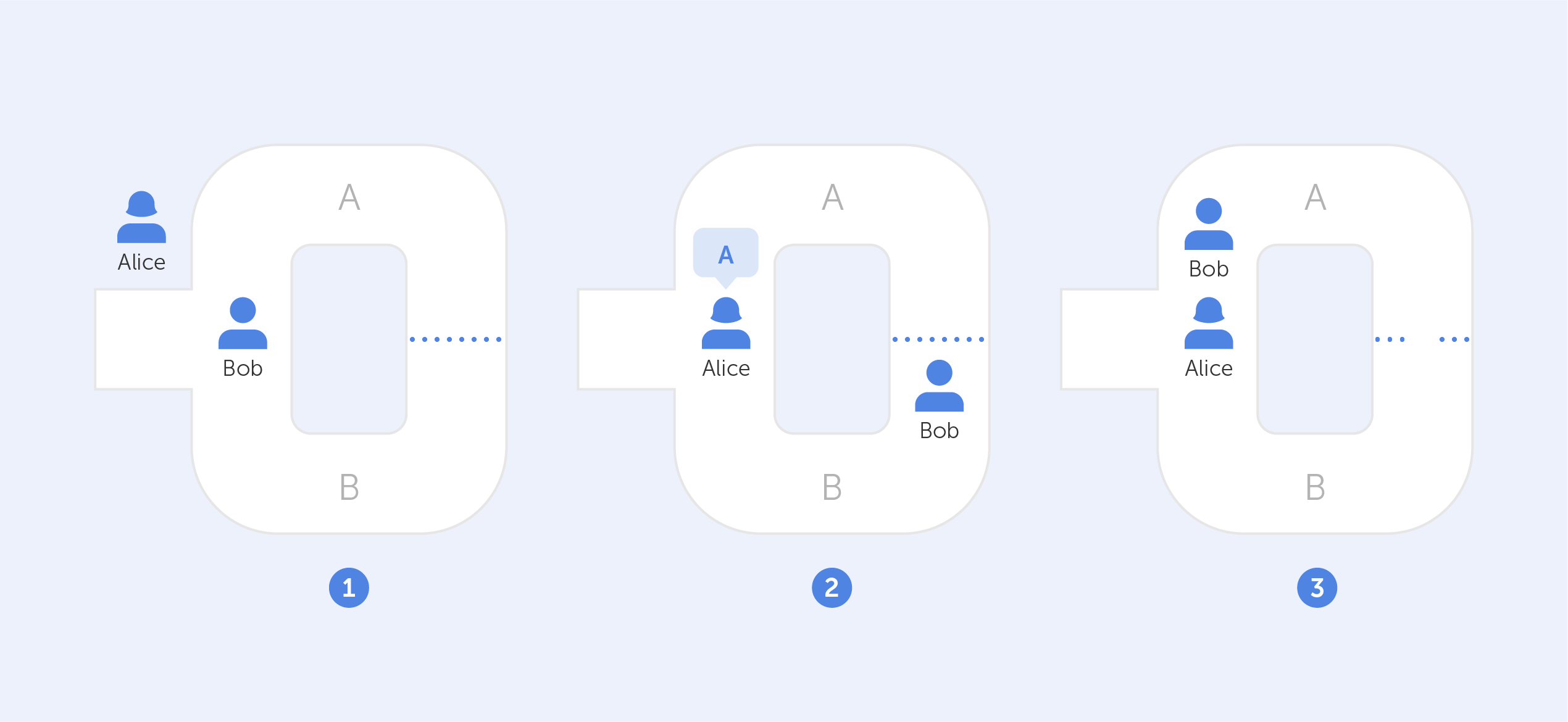
Assume that two characters, Alice and Bob, find themselves at the mouth of a cave with two independent entrances leading to two different paths (A and B). A door inside the cave connects both paths, but it can only be unlocked with a secret code. This code belongs to Bob (the 'tester,') and Alice (the 'verifier,') wants to buy it, but first, she wants to make sure Bob isn't lying.
How can Bob demonstrate to Alice that he has the code without divulging its contents? They perform the following to achieve this: Bob enters the cave via one of the entrances at random while Alice waits outside (A or B). Once inside, Alice approaches the front door, summons Bob, and instructs him to use one of the two exits. Bob will always be able to return by the path that Alice used since he knows the secret code.
Bob will always be able to return via the path that Alice directs him to, even if it does not coincide with the one he chose in the first place, because he can unlock the door and depart through the other side with the secret code.
But wait a minute, there is still a 50% chance that both Alice and Bob chose the same path, right? It is correct indeed, however, if this exercise is repeated several times, the likelihood that Bob will escape along the same path chosen by Alice without possessing the code decreases until it is almost impossible. Conclusion? If Bob leaves this path a sufficient number of times, he has unmistakably shown to Alice that his claim of holding the secret code is true. Moreover, there was no need to reveal the actual code in this case.
You can find out more about the Bob and Alice metaphor here.
Got it, so how is it used?
As for right now, ZKP is developing hand in hand with blockchain technology.
Zcash is a crypto platform that uses a unique iteration of zero-knowledge proofs (called zk-SNARKs). It allows native transactions to stay entirely encrypted while still being confirmed under the network's consensus rules. It’s a great example of this technology being used in practice.
Even though zero-knowledge proofs have a lot of potential to change the way today's data systems verify information, the technology is still considered to be in its infancy — primarily because researchers are still figuring out how to best use this concept while identifying any potential flaws. This, however, doesn’t stop us from using this protocol in our products! ;)
For a deeper understanding of the technical aspects and history behind this protocol, we recommend watching this video on YouTube.
What is Zero-knowledge Proof?
The Secure Sockets Layer (SSL) and the Transport Layer Security (TLS) cryptographic protocols have seen their share of flaws, like every other technology. In this article, we would like to list the most commonly-known vulnerabilities of these protocols. Most of them affect the outdated versions of these protocols (TLS 1.2 and below), although one major vulnerability was found that affects TLS 1.3.
POODLE
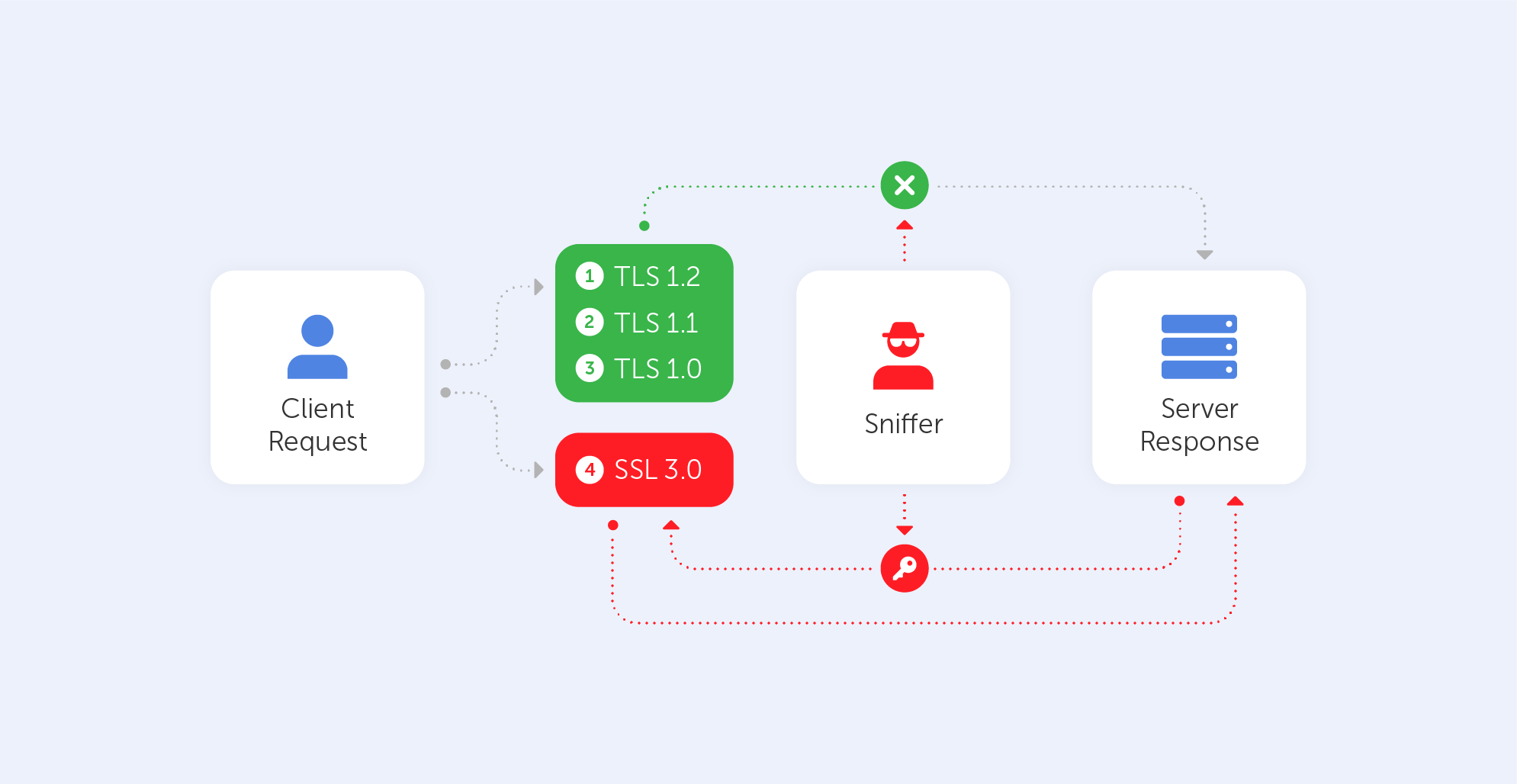
This cute name should not misguide you – it stands for Padding Oracle On Downgraded Legacy Encryption. Not that nice after all, right? It was published in October 2014 and it takes advantage of two peculiar facts. The first one is that some servers/clients still support SSL 3.0 for interoperability and compatibility with legacy systems. The second one is a vulnerability related to block padding that appears in SSL 3.0. Here is a link to that vulnerability on the NIST NVD database.
How does it work?
As mentioned before, this vulnerability comes from the Cipher Block Chaining (CBC) mode. Those block ciphers use blocks of a fixed length, so if the data in the last block is shorter than the block’s size, it is filled by padding. The server, of course, ignores such padding by default, it only checks whether the length is correct and verifies the Message Authentication Code (MAC) of the plaintext. In practice, this means that the server cannot verify if the content inside the padding has been altered in any way.
An attacker is able to modify padding data and then simply waits for the server’s response. Attackers can recover the contents byte-by-byte by watching server responses and altering the input. It usually takes no more than 256 attempts to reveal one byte of a cookie, which equates to a maximum of 4096 queries for a 16-bit cookie. Just by using automated scripts, the hacker may retrieve the plaintext char by char. Such a plaintext may be anything from a password to a cookie or a session. So, without even knowing the encryption method or key, a sniffer may easily decipher a block.
BEAST
The Browser Exploit Against SSL/TLS attacks was disclosed in September 2011. It affects browsers that support TLS 1.0, because this early version of the protocol has a vulnerability when it comes to the implementation of the above-mentioned CBC mode. Here’s a link to it in the NIST NVD database.
How does it work?
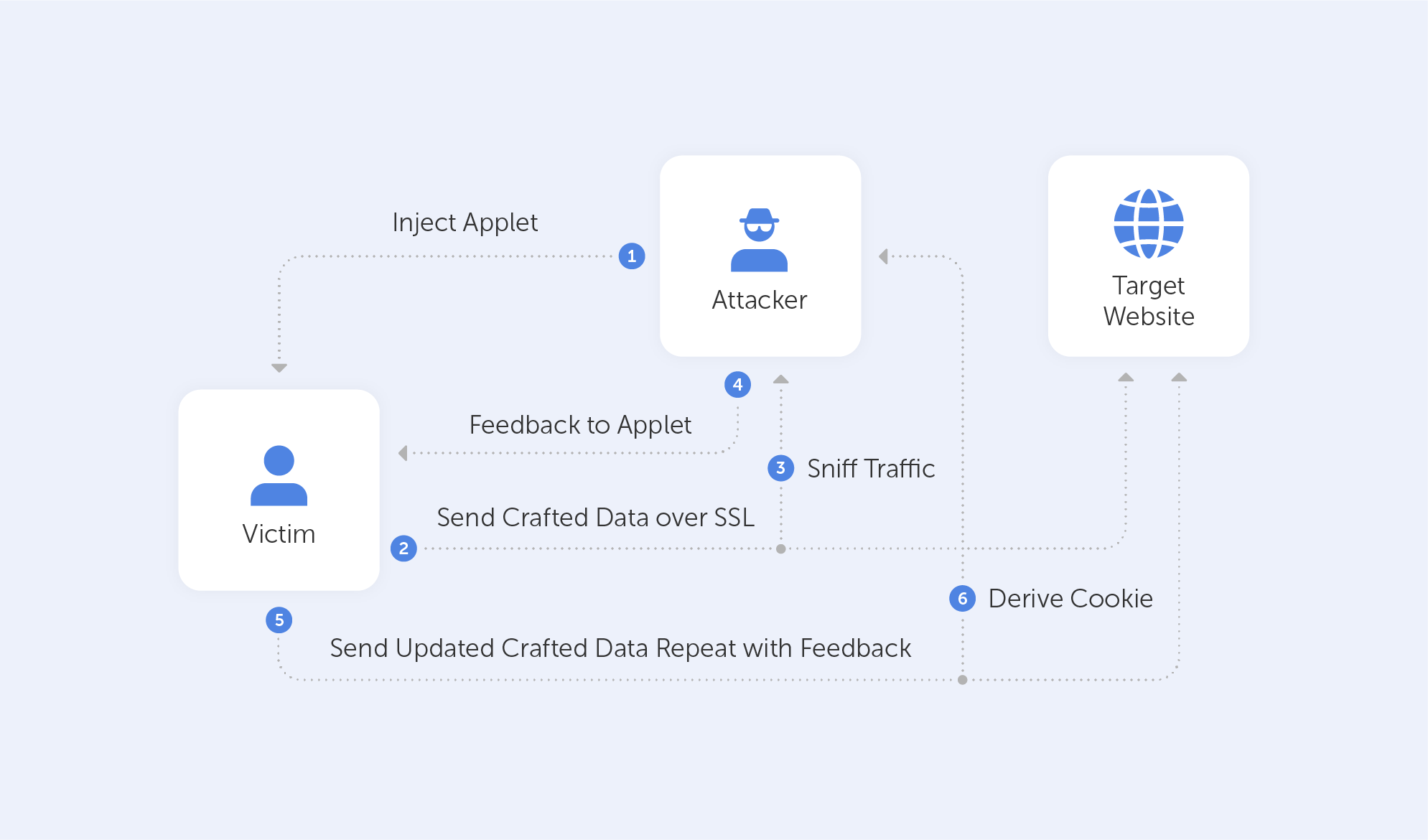
This kind of attack is usually client-side, so in order for it to succeed, an attacker should, in one way or another, have some control of the clients’ browser. After getting access to a browser, the attacker would typically use MITM to inject packets into the TLS stream. After such an injection, the only thing left is to guess the Initialization Vector (IV) – a random block of data that makes each message unique. This is used with the injected message and then simply compared with the results of the needed block.
CRIME
The Compression Ratio Info-leak Made Easy (CRIME) vulnerability affects TLS compression. The Client Hello message optionally uses the DEFLATE compression method, which was introduced to SSL/TLS to reduce bandwidth. The main method used by any compression algorithm is to replace repeated byte patterns with a pointer to the first instance of such sequences. As a result – the bigger the repeated sequences, the more effective such a compression is. You can visit this link to locate this vulnerability in the NIST NVD database.
How does it work?
Let’s imagine that a hacker is targeting cookies. He knows that the targeted website creates a cookie for each session named ‘ss’. The DEFLATE compression method replaces repeated bytes and our antagonist knows that. Therefore, he injects Cookie:adn=0 to the victim’s cookie. The server would, of course, append 0 to the compressed response, because Cookie:adn= has been already sent, so it is repeated.
After that, the only thing for an attacker to do is to inject different characters and then monitor the size of the response.
The injected character is contained in the cookie value if the answer is shorter than the first one, hence the compression. The response will be longer if the character is not in the cookie value. Using this strategy, an attacker can recreate the cookie value using the server's feedback.

By the way, the BREACH attack is very similar to CRIME, but it targets HTTP compression instead.
Heartbleed
Heartbleed was a major vulnerability discovered in the OpenSSL (1.0.1) library's heartbeat extension. This extension is used to maintain a connection so long as both participants are online. Here is its link on our beloved NIST NVD database.
How does it work?
The client sends the server a heartbeat message with a payload containing data and its size + padding. The server will respond with the same heartbeat request as the client.
The vulnerability comes from the fact that if the client sent a false data length, the server would respond with a heartbeat response containing not only the data received by the client but, because it needs to fill the length of the message, also with random data from its memory. A very unfortunate technical solution, isn’t it?
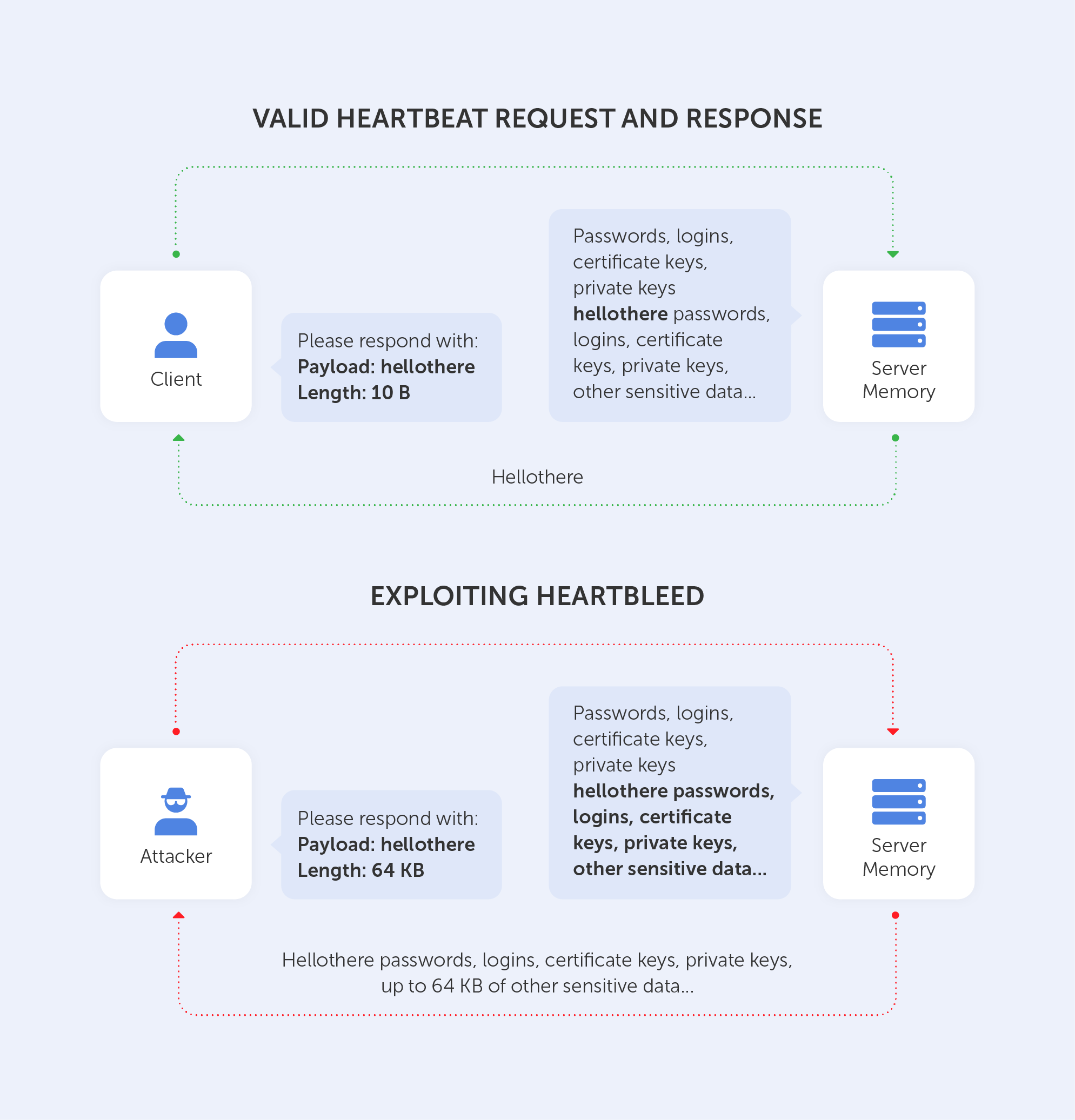
Leaking such unencrypted data may result in a disaster. It is well-documented that by using such a technique, an intruder may obtain a private key to the server. Moreover, if the attacker has the private key – well, that means he’s able to decrypt all the traffic to the server. I guess we don’t need to tell you why that’s no good, right?
The entire list of vulnerabilities may be found in this wonderful report by the Health Sector Cybercecurity Coordination Center. It not only lists all above-mentioned techniques in a very informative manner but also provides a very neat table of all ‘Known Threats to TLS/SLS’ (pp. 24-26).
Instead of a long conclusion, let’s just look at the last page of that report:
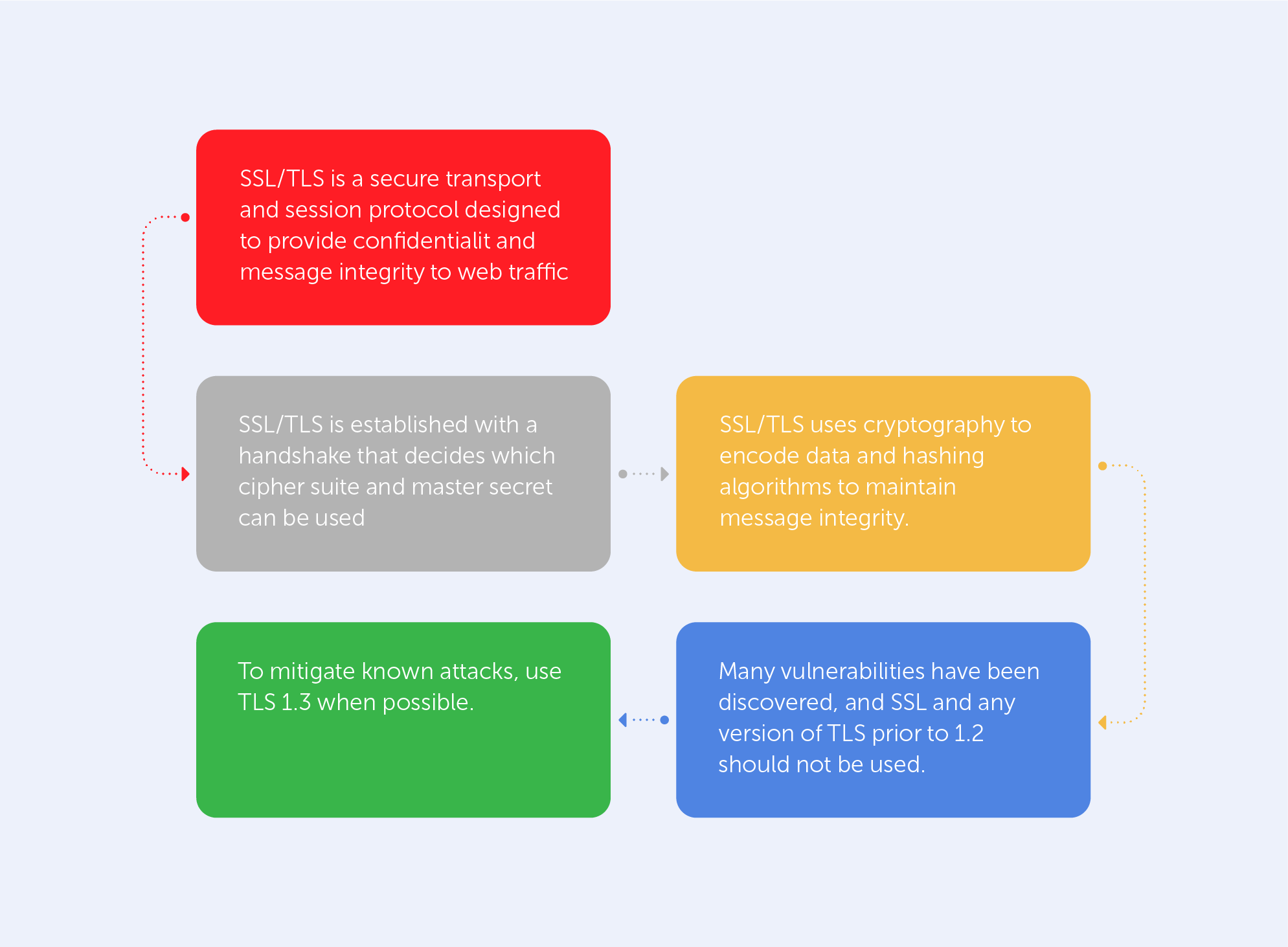
The green cell of the chart explicitly states how to get rid of most known vulnerabilities. Indeed, if you’re not interested in trawling through the nooks and crannies of the Library of Alexandria’s floor on Cybersecurity, the best way to track existing SSL/TLS vulnerabilities is by visiting csrc.nist.gov once in a while. You might even consider making it your homepage.
What are SSL Vulnerabilities?
Security, security, security… There is no way one can underestimate the importance of it when it comes to caring for private files and sensitive data. As long as the world of cybersecurity is privy to the constant conflict between hackers and programmers, fully protecting yourself and your business will forever be impossible. But, as we know, hackers aren’t always using state-of-the-art techniques. Often, they’re still getting in by guessing your username and password.
Most popular kinds of technology are under a constant barrage of hacking attempts, which is why it is so important to follow simple protocols to save yourself both time and money. One of such technologies is SSL/TLS. It is used on almost every web service, and even though it may seem straightforward to set up, there are many arcane configurations and design choices that need to be made to get it ‘just right’.
This guide will provide you with a short ‘checklist’ to keep in mind when setting up or maintaining SSL/TLS with a focus on security. All information is accurate and up to date as of December 2021 and is based on both our experience and other guides made on this topic.
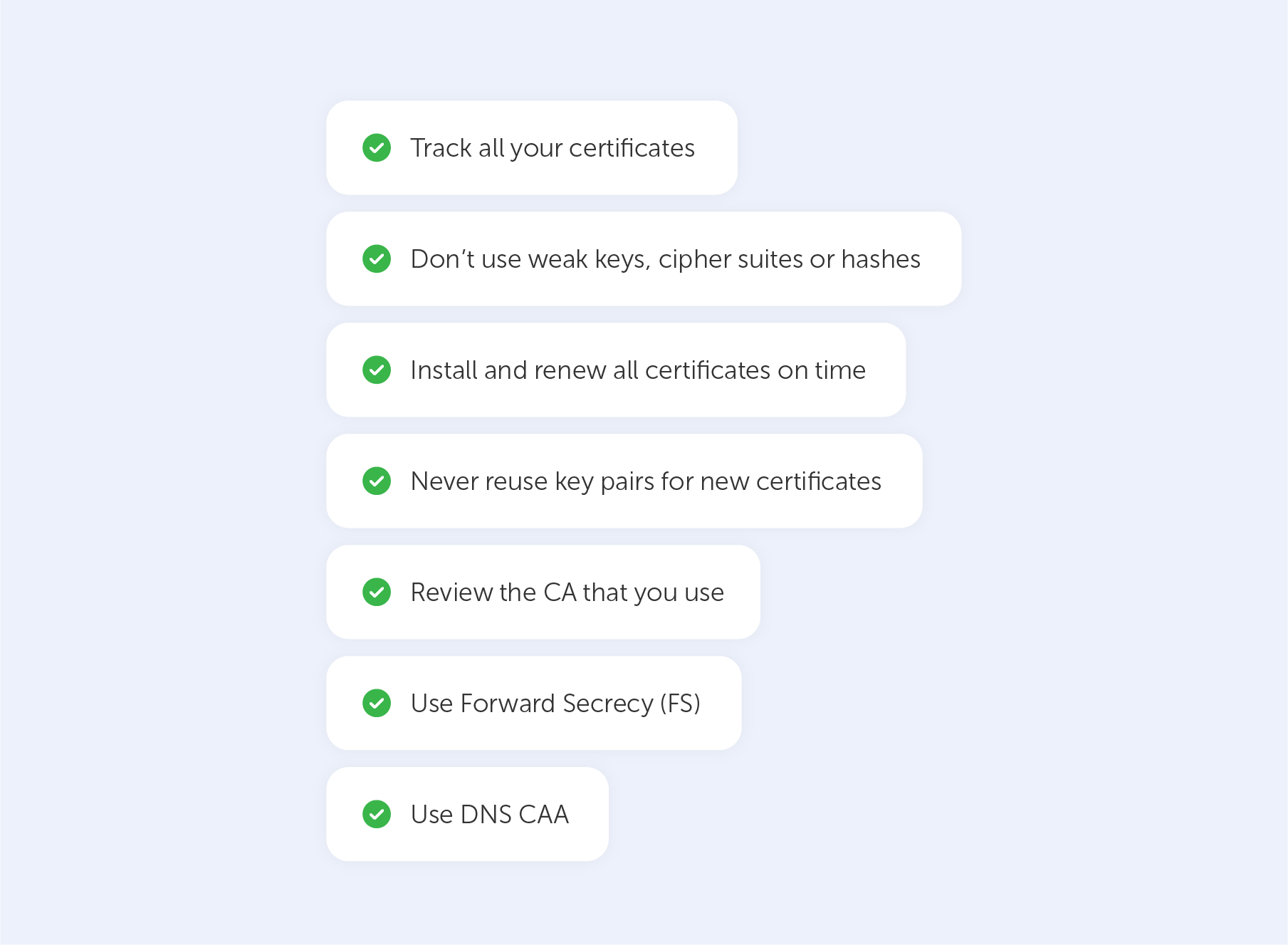
Track all your certificates
First and foremost, you should check up on all existing certificates that are used by you and your organisation. This covers all information about them, such as their owners, locations, expiration dates, domains, cipher suites, and TLS versions.
If you don’t know about, or don’t track existing certificates as well as weak keys and cipher suites, you expose yourself to security breaches connected to expiring certificates.
An easy way to list all your certificates is to get them from your CA. This may not work if you used self-signed certificates, which require additional attention in terms of tracking/listing. The second way, which is typically quite effective, is to obtain certificates using network scanners. Hopefully, the enormous number of certifications that you were unaware of will not surprise you. Your certificate ‘inventory’ should focus on details such as OS and applications like Apache, just because your organization could be vulnerable to exploits that attack specific versions of things like OpenSSL (i.e., Heartbleed).
So, your list of certificates should include:
- Certificates issued
• Certificate types
• Key sizes
• Algorithms
• Expiration dates - Certificate locations
- Certificate owners
- Web server configurations
• O/S versions
• Application versions
• TLS versions
• Cipher suites
Don’t use weak keys, cipher suites or hashes
Every certificate has a public key and a signature, both of which may be vulnerable if they were created with outdated technology. On public web servers, certificates with key lengths of less than 2048 bit or those that employ older hashing algorithms like MD5 or SHA-1 are no longer allowed. These may, however, be found on your internal services. If that's the case, you'll need to upgrade them.
The requirement to check TLS/SSL versions and cipher suites supported on your web servers is much more crucial than finding certificates with weak keys or hashes.
The following versions are outdated and must never be used:
• SSL v2
• SSL v3
• TLS 1.0
• TLS 1.1
Instead, enable TLS 1.2 and TLS 1.3.
The following cipher suites are vulnerable, and must be disabled:
• DES
• 3DES
• RC4
Instead, use modern ciphers like AES.
Install and renew all certificates on time
We recommend renewing a certificate at least 15 days before it expires to allow time for testing and reverting to the prior certificate if any problems arise.
Users should be notified when certificates expire, regardless of the mechanism you employ. Before expiration, the system should alert users automatically and at regular intervals (e.g., 90 days). Self-signed certificates should never have an expiration date of more than 30 days.
Never reuse key pairs for new certificates
By the same token, never reuse CSRs (Certificate Signing Requests) — this will automatically reuse the private key. Reusing keys leads to key pair vulnerability. Don’t be lazy when it comes to your security.
Review the CA that you use
Your certificates are only as trustworthy as the CA that issues them. All publicly trusted CAs are subject to rigorous third-party audits to maintain their position in major operating system and browser root certificate programs, but some are better at maintaining that status than others.
Use Forward Secrecy (FS)
Also known as perfect forward secrecy (PFS), FS assures that a compromised private key will not also compromise past session keys. To enable it, use at least TLS 1.2 and configure it to use the Elliptic Curve Diffie-Hellman (EDCHE) key exchange algorithm. The best practice here would be to use TLS 1.3 as it provides forward secrecy for all TLS sessions using the Ephemeral Diffie-Hellman key exchange protocol ‘out of the box’.
Use DNS CAA
DNS CAA is a standard that allows domain name owners to restrict which CAs can issue certificates for their domains. In September 2017, the CA/Browser Forum mandated CAA support as part of its certificate issuance standard baseline requirements. The surface area prone to attack is certainly shrunk with CAA in place, effectively making sites more secure. If CAs have an automated mechanism in place for certificate issuance, they should check for DNS CAA records to prevent certificates from being issued incorrectly. It is advised that you add a CAA record to your certificate to whitelist a CA. Add certificate authorities (CAs) that you trust.
Keep in mind that encryption is not an option.
Enforce encryption across your entire infrastructure — no 'bald spots' should remain. Leaving elements of your infrastructure unprotected is like forgetting to lock the door when you leave — it's not a good idea.
The practices that we’ve mentioned in this list are more about common sense, rather than knowledge acquired through the ultra-secret bureau. When it comes to security, you should always keep your infrastructure up-to-date. New vulnerabilities pop up every day, but still, we, humans, pose the biggest threat of all. In other words, human error has more to answer for than we might first believe. Because of this, double-check everything you do. Security protocols should be easy to follow not only by the person who creates them but also by everyone who interacts with your infrastructure — users and employees alike.
With such a checklist, it’s impossible to shine a light on each and every nook and cranny, so for those of you who want to ensure that you’re following all best practices, consider checking out this list.
SSL best practices to improve your security
Most web servers across the internet and intranets alike use SSL certificates to secure connections. These certificates are traditionally generated by OpenSSL – a software library containing an open-source implementation of the SSL and TLS protocols. Basically, we’re looking at a core library, providing us with a variety of cryptographic and utility functions. Because of its ease-of-use and, most importantly, because it’s open-source (so, free), it managed to make its way to the top, and now, it’s the industry standard.
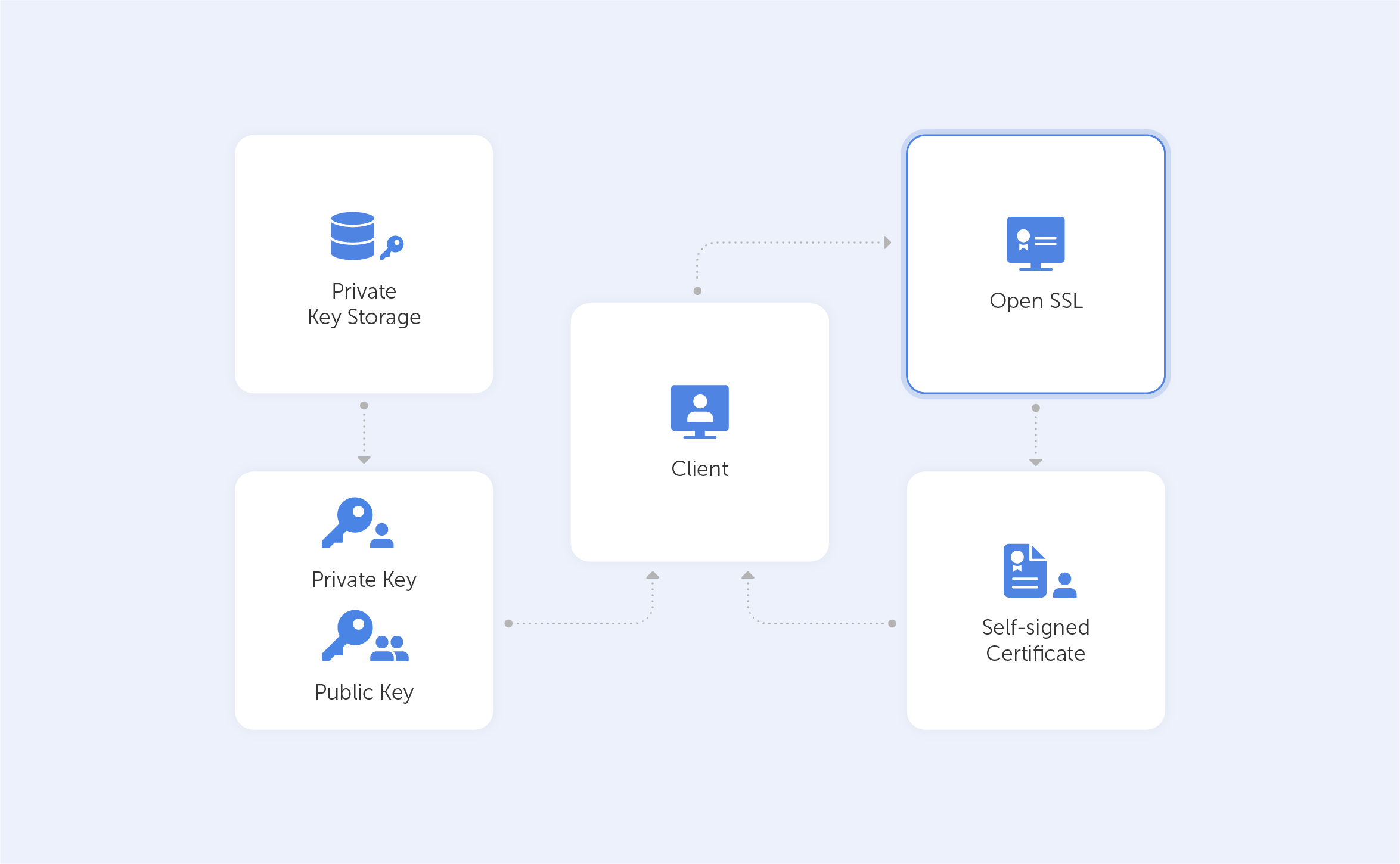
OpenSSL is available for Windows, Linux and MacOS. So, before you get started, make sure that you have OpenSSL installed on your machine. Here’s a list of precompiled binaries for your convenience. But, to be honest, the OS doesn’t really matter here too much – the commands are going to be identical in our case.
In this tutorial, we’ll show you how easy it can be to generate self-signed certificates with OpenSSL.
Such a self-signed certificate is great if you want to use HTTPS (HTTP over TLS) to secure your Apache HTTP or Nginx web server, and you know that your certificate doesn’t need to be signed by a CA.
How should I use OpenSSL?
OpenSSL is all about its command lines. Below, we’ve put together a few common OpenSSL commands that regular users can fiddle about with to generate private keys. After each command, we’ll try to explain what that exact line of code does by breaking it down into its constituent parts. If you fancy studying all of the commands, take a look at this page.
How can I generate self-signed certificates?
Let’s start! First and foremost, we want to check whether we have OpenSSL installed. To do that, we need to run:
openssl version -aIf you get something like this, you’re on the correct path:
OpenSSL 3.0.0 7 sep 2021 (Library: OpenSSL 3.0.0 7 sep 2021)
built on: Tue Sep 7 11:46:32 2021 UTC
platform: darwin64-x86_64-cc
options: bn(64,64)
compiler: clang -fPIC -arch x86_64 -O3 -Wall -DL_ENDIAN -DOPENSSL_PIC -D_REENTRANT -DOPENSSL_BUILDING_OPENSSL -DNDEBUG
OPENSSLDIR: "/usr/local/etc/openssl@3"
ENGINESDIR: "/usr/local/Cellar/openssl@3/3.0.0_1/lib/engines-3"
MODULESDIR: "/usr/local/Cellar/openssl@3/3.0.0_1/lib/ossl-modules"
Seeding source: os-specific
CPUINFO: OPENSSL_ia32cap=0x7ffaf3bfffebffff:0x40000000029c67afThis code effectively specifies the SSL version that you have installed and some other details.
Now, the first important thing on our agenda is to generate a Public/Private keypair. To do this, we ought to punch in the following command:
openssl genrsa - out passwork.key 2048genrsa – is the command to generate a keypair with the RSA algorithm;
-out passwork.key – this is the output key file name;
2048– key size. Make sure to double-check your requirements at this stage, because that value may change depending on your use case.
Now we have the file ‘passwork.key’ in a directory that we’ve specified. Once we’ve created a file we can, for example, extract the public key by running:
openssl rsa -in passwork.key -pubout -out passwork_public.keyrsa – we ought to specify the algorithm that we used;
-in passwork.key – we take the existing keypair;
-pubout – here, we take only public key;
-out passwork_public.key – we’re exporting this as a file with name passwork_public.key.
Now we may proceed to creating a CSR – Certificate Signing Request. In a real production scenario, such a CSR is forwarded to the CA which signs it on your behalf, so you get a certificate. But for the sake of our tutorial, we’ll create a CSR and self-sign it.
The command to create a CSR is as follows:
openssl req -new -key passwork.key -out passwork.csrreq -new – here, we’re specifying that we want to create something new;
-key passwork.key – here, we’re specifying the key that we will use;
-out passwork.csr – here, we’re specifying the output file.
After pressing ‘Enter’ you’ll see something like this:
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields, there will be a default value,
If you enter '.', the field will be left blank.Enter the required data. For the purposes of our tutorial, we’ve entered the following fake values:
-----
Country Name (2 letter code) [AU]:US
State or Province Name (full name) [Some-State]:FL
Locality Name (eg, city) []:Tallahassee
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Passwork
Organizational Unit Name (eg, section) []:.
Common Name (e.g. server FQDN or YOUR name) []:*.passwork.com
Email Address []:[email protected]
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:One of the most important fields is Common Name, which should match the server name or FQDN where the certificate is going to be used.
After all the above-mentioned steps, we’ll have our CSR file fully generated. In the real world, at this stage, we’d want to verify our CSR file, just so we’re not passing the wrong file to the CA. Also, it’s good practise to double-check whether the FQDN is correct.
Having all that in mind, we run:
openssl req -text -in passwork.csr -noout -verifyThe output, in our case, would be:
Certificate request self-signature verify OK
Certificate Request:
Data:
Version: 1 (0x0)
Subject: C = US, ST = FL, L = Tallahassee, O = Passwork, CN = *.passwork.com, emailAddress = [email protected]
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:dd:c9:5a:27:82:00:0e:cc:43:c2:99:3a:e7:0a:
b7:c2:96:06:f1:30:d6:3e:de:7c:6d:f1:98:66:cf:
9d:8a:9c:09:43:a9:ab:59:0f:19:29:44:ec:2d:73:
47:38:94:78:1b:4f:16:b6:4a:2b:45:55:0f:39:56:
96:c3:53:e6:65:db:f7:91:b1:cb:36:e7:4b:cd:cd:
bb:6b:36:9e:92:c9:5e:cc:09:de:f6:ca:43:66:14:
21:b1:f9:37:56:22:6a:4f:3c:c5:08:5a:ab:81:19:
88:a3:ee:87:9c:c6:1c:d5:42:71:35:33:cd:f4:ed:
59:81:c6:eb:f3:02:da:43:e0:ce:f9:a5:6a:ca:d4:
39:81:b3:17:68:4b:9a:a4:e0:41:55:c7:46:5d:38:
05:f7:cc:7b:0b:80:b8:63:f4:91:81:d8:80:7c:00:
11:e0:55:19:07:23:4a:5d:08:8e:8d:fc:c6:05:59:
12:d1:7a:de:50:c4:d3:41:5f:b2:73:33:8b:2d:b7:
80:a3:f4:66:b1:80:d1:22:01:71:b7:5d:75:a7:df:
ae:e8:bd:22:32:30:71:54:56:ae:a6:b3:38:be:29:
bb:af:be:01:65:fb:d4:66:84:b0:f0:fb:4b:58:c2:
0e:3e:ee:9c:01:05:2e:02:7a:e1:42:71:c2:66:80:
f7:27
Exponent: 65537 (0x10001)
Attributes:
(none)
Requested Extensions:
Signature Algorithm: sha256WithRSAEncryption
Signature Value:
84:db:c8:7c:62:f3:54:85:c4:df:b9:c5:f5:2d:7a:c9:01:b1:
2b:2b:69:a4:d6:ff:e8:8c:ef:39:dd:27:52:de:ba:58:67:5e:
9a:37:c2:5c:2e:1c:58:7e:5b:f6:5d:cf:c5:f7:39:17:20:5f:
82:bb:a5:52:bb:23:b9:b4:1a:c5:99:8d:1e:68:c9:1c:7e:a1:
e1:39:9b:5e:b6:d4:22:17:38:fe:c8:8e:a5:82:da:ab:c9:ae:
63:e6:42:5a:e0:09:50:a5:86:5a:8b:82:0c:0b:df:40:54:0d:
9f:ec:b5:71:79:08:84:04:85:fc:6c:7b:63:38:37:b0:6d:20:
10:2b:51:8a:dd:36:e6:92:c0:b6:9c:2e:86:c9:5a:55:3c:52:
26:2b:8c:3d:80:35:fa:2a:40:c0:9e:d3:f2:e5:0e:78:e8:ea:
d2:6f:ef:00:77:45:e5:1b:cc:df:da:52:b2:14:c9:23:09:f0:
9b:5e:f5:9d:7d:df:e6:82:d1:b7:3a:a4:34:b5:df:bb:d6:fa:
fe:85:47:6e:63:51:c3:d2:9d:11:43:16:2c:3e:df:44:0b:a7:
08:1a:58:d5:f3:3d:49:a0:52:b7:6f:85:06:5d:da:3f:10:db:
33:4f:71:38:6d:f6:e2:0e:ad:e1:74:35:27:09:a5:90:92:18:
fc:96:30:54As you can see, it lists crucial data that you provided when you answered questions related to the CSR. Check the values and if something is wrong – simply re-generate the CSR before you pass it on to the CA.
As we mentioned before, instead of passing our CSR to the CA, we’ll create a self-signed certificate. In order to do that, we ought to enter the following:
openssl x509 -in passwork.csr -out passwork.crt -req -signkey passwork.key -days 30The ‘X509’ command is our multi purpose certificate utility;
-in passwork.csr represents our CSR;
-out passwork.crt is the name and file extension for our certificate;
-req signkey passwork.key – here, we’re specifying the keypair that we want to use to sign our certificate;
-days 30 – this is an expiration time interval for our certificate.
The passwork.crt certificate file has now been generated, so it’s ready to go! Pretty easy, right? Well, it gets a lot easier when we remember that we can generate a self-signed certificate by just entering:
openssl req \
-newkey rsa:2048 -nodes -keyout passwork.key \
x509 -days 365 -out domain.crtHere, a temporary CSR is generated, so we don’t have to enter all the data manually.
Please bear in mind that in real-life situations, you should follow best practice when creating a private key, they can be easily generated and therefore compromised.
Conclusion
We’ve barely touched the functionalities within OpenSSL, but as you can see, it’s not as complicated as many people first think – that’s why it’s loved far and wide. If you’ve still got any unanswered and burning questions, feel free to check out the frequently-asked questions (FAQ) page on the OpenSSL project’s website. If that’s not enough and you’re really looking for a deep dive – we can’t recommend this free e-book highly enough.
What OpenSSL is used for?
The SSL/TLS protocol’s job is to ensure security through authentication. It was designed to encrypt data transmitted over open networks and, as a result, protect against interception and spoofing attacks. TLS also authenticates communicating parties, which leaves us with a pretty trusting environment. It goes without saying that security through authentication is essential for a successful business in the 21st century.
If we closely observe the way in which SSL works, it becomes very clear very fast, that to establish the ‘trusting environment’, SSL certificates need to be signed and validated by a trusted Certificate Authority (CA). Now, while everyone trusts the CA, by extension, they are able to trust those with its certification. Traditionally, organizations have used CAs to sign their SSL/TLS certificates, but with an influx of digital products, a huge amount of software being developed and tested in addition to an all-time data breach record, many companies are switching to self-signed certificates.
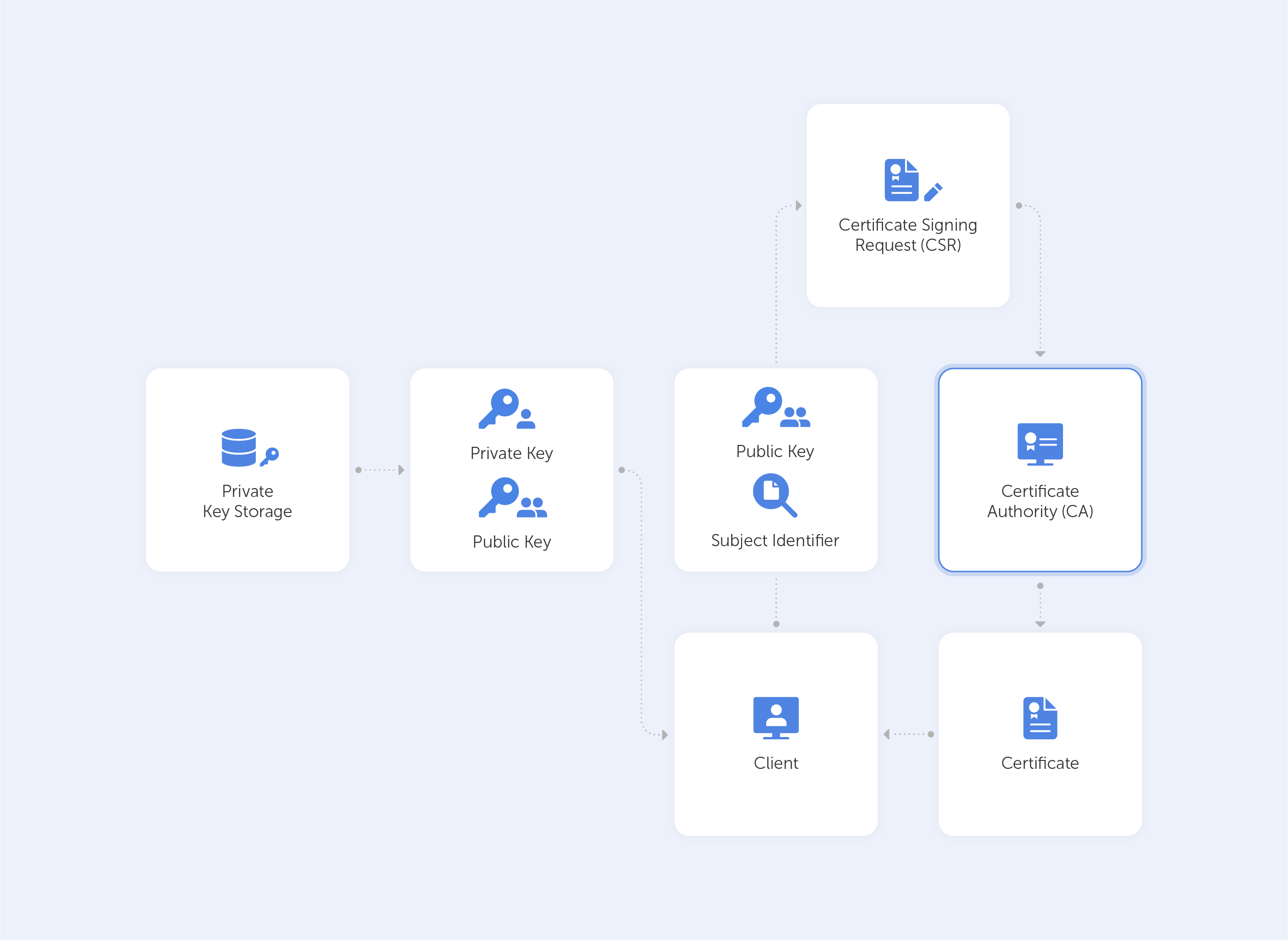
What is a Self-Signed SSL Certificate?
A self-signed certificate is a digital certificate that hasn’t been signed by a publicly trusted CA. Instead, it is issued and signed by the entity that is responsible for the software. This, on the one hand, makes deployment pretty frictionless, but on the other, it comes with additional risk, especially when poorly implemented.
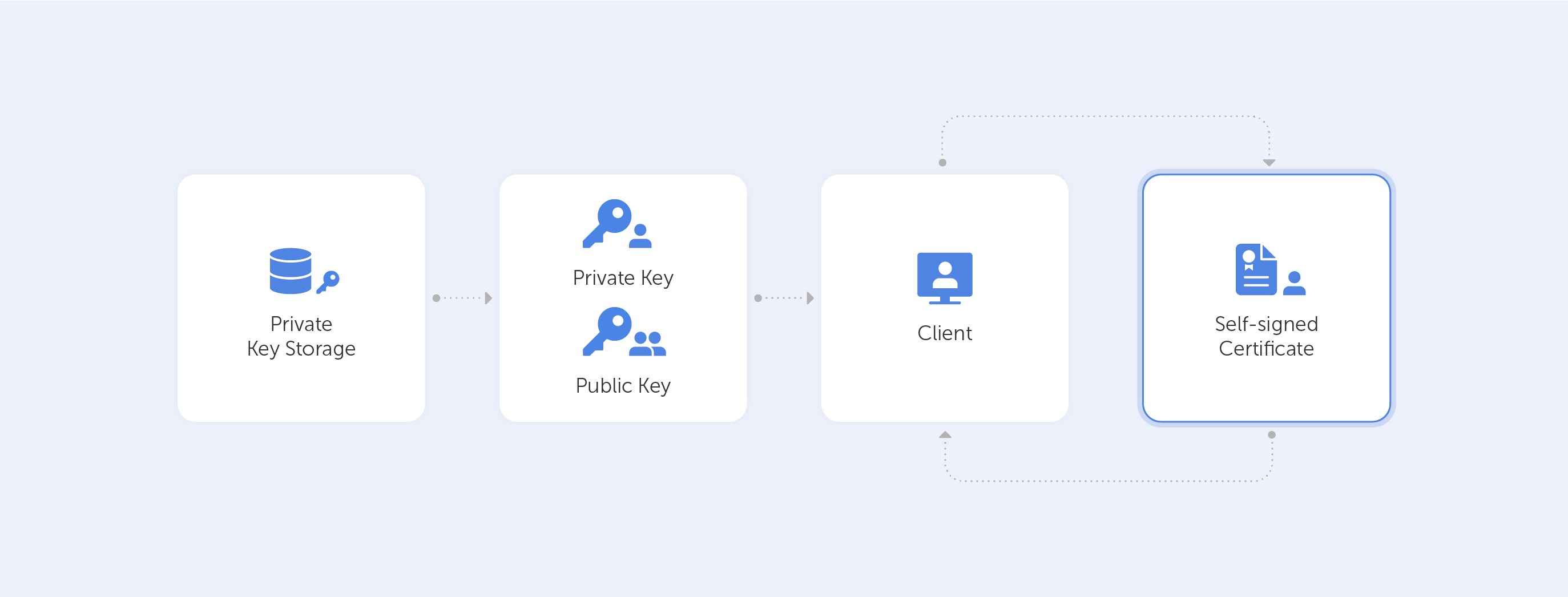
Although they can be risky, self-signed certificates are incredibly widespread. These certificates are available with no associated costs and can be requested easily by anyone, which is fantastic for internal testing environments or web servers that are otherwise locked for external users. Moreover, such a certificate still uses the same encryption methods as other, paid SSL/TLS certificates – that’s a piece of very good news for organizations because nobody wants their data leaking. As long as the CA doesn’t require a certificate expiry date, a self-signed certificate may be issued once and used till the end of time. This is used, for example, when working on some secret projects or simply with internal data.
For many companies that use self-signed certificates, the biggest advantage is, of course, independence. All security infrastructure is encapsulated inside the internal network, so even if such a network isn’t connected to the web at all – it’ll still work as intended.
Although this looks very convenient on the surface, it is one of the major concerns when dealing with these types of certificates. Offline, they aren’t able to receive security updates in response to discovered vulnerabilities, nor meet the certificate agility which is essential to secure today's modern enterprise.
Another challenge that arises when dealing with self-signed certificates is that responsible departments often lack visibility over how many were issued, where they are used, by whom, and also how the private key is stored. It’s hard enough to keep track of certificates issued by different public and private CAs. It’s almost impossible to track all self-signed certificates without an additional request process.
Pros:
- Fast and easy to issue;
- Useful in test environments;
- Flexibility;
- Independence;
- No expiration date.
Cons:
- No security updates;
- Can’t be easily revoked;
- Lack of visibility and control.
Let’s imagine that our internal network has been breached. If we use self-signed certificates, there is literally no way of knowing if it, and private keys associated with it, have been compromised. Once compromised, such a certificate may be used to spoof identities and gain access to important data, especially considering the fact that, unlike CA-issued certificates, self-signed certificates cannot be revoked and, as we mentioned before, have no expiration date. You cannot simply ‘revoke’ a private key in such a situation.
So, why are self-signed certificates still in use? The simple answer is that it’s convenient. The routine manual process of submitting a certificate signing request (CSR) and waiting hours for verification is just horrible. To save time and frustration, it makes more sense to opt for self-signed certificates.
So the biggest question on self-signed certificates of any type is not how to issue them, but how to properly implement them inside an organisation. It’s like making sushi – the recipe is very simple, but the devil is in the details.
Some risks may be indirect – let’s imagine we’re looking to use a self-signed certificate to provide access to an employee portal. It will cause any default browser to alert the user with warnings. As these alerts can be ignored, many organisations tend to instruct their employees to do exactly that – ignore warnings. The safety of the internal portal is assured, so there is no direct harm, but, at the same time, employees ‘learn’ to ignore alerts and warnings the same way we all ignore ads on websites. Such practices make the organisation overall more vulnerable. The crux of the matter is that employees just don’t provide essential feedback on time if something goes very wrong.
To get the best out of self-issued certificates and mitigate the risks involved, we recommend using OpenSSL to issue certificates. It is de facto an industry standard. But, as mentioned before, this is not enough. Correct implementation is even more important than the tools used. After all, a top of the line DeWalt grinder is going to be useless if you’re using it to hammer in a nail. So, when implementing a self-signed certificate try to follow these best practices:
- Limit the expiration period, it should be as short as possible. Never use certificates that don’t feature an expiry date.
- Limit usage. Never create ‘universal certificates’ that open all doors at once.
- Use a meaningful and informative ‘subject’ record. Everybody should understand what the certificate is being used for.
- Make sure that the algorithm used for the signature is at least SHA256WITHRSA (which is the default in OpenSSL).
- Create only encrypted private keys.
- Use elliptic curve keys as opposed to the default RSA ones; they provide a number of benefits over RSA.
- Most importantly, create a repeatable/scriptable process for issuing certificates and keys. OpenSSL is a de-facto standard command-line tool that can be used as the basis for this process.
Self-signed certificates are fast and easy to use, they are great for test environments, or when providing encrypted access to internal data. They provide independence and are free to use. That is why they are used across the board in so many companies. On the whole, there’s really no other way to do things right. But remember, SSL/TLS self-signed certificates are like fugu fish – it is delicious when cooked well, but you’ll drop dead if the chef’s on his lunch break.
What is a Self-Signed Certificate?
Stuck between a proxy and a hard place
Let’s imagine that you’re managing a small team, all of whom are coming back to work after a relaxing furlough period. Of course, you’re going to notice a drop in productivity; your team has become accustomed to browsing YouTube between Zoom calls and messaging their friends on Facebook. The solution? A ‘forward proxy’, which is the kind of proxy you’re likely to be familiar with. This will make sure that employees are prompted to get the ‘Pass’ back to work, should they try to access social networking.
Now, perhaps you have an update scheduled for your website, but you’re still not sure whether you’ve caught all the bugs. Or, maybe you want to scale your infrastructure in a ‘plug'n'play’ way. How are you going to test out new features on a certain percentile of your users? Here, you’ll find faithful solace in the almighty powers of the ‘reverse proxy’.
Whether you’re looking to learn more about forward or reverse proxies, today we’ll take a deep dive and explore how you can level up your business’ IT infrastructure through their use.
So, what’s a proxy server?
A proxy server is effectively a gateway between networks or protocols. They usually separate the end-user from the server. They also can alter or redirect the connection or data that passes through. Moreover, proxies come in a variety of 'tastes and colours' depending on their use case, the system complexity, privacy requirements, and so on.
If you’re using a proxy server, any data you send to the external network ought to flow through it beforehand. Also, it works both ways, so you, the client, cannot be reached by someone on the external net without that data first being sent through the proxy.
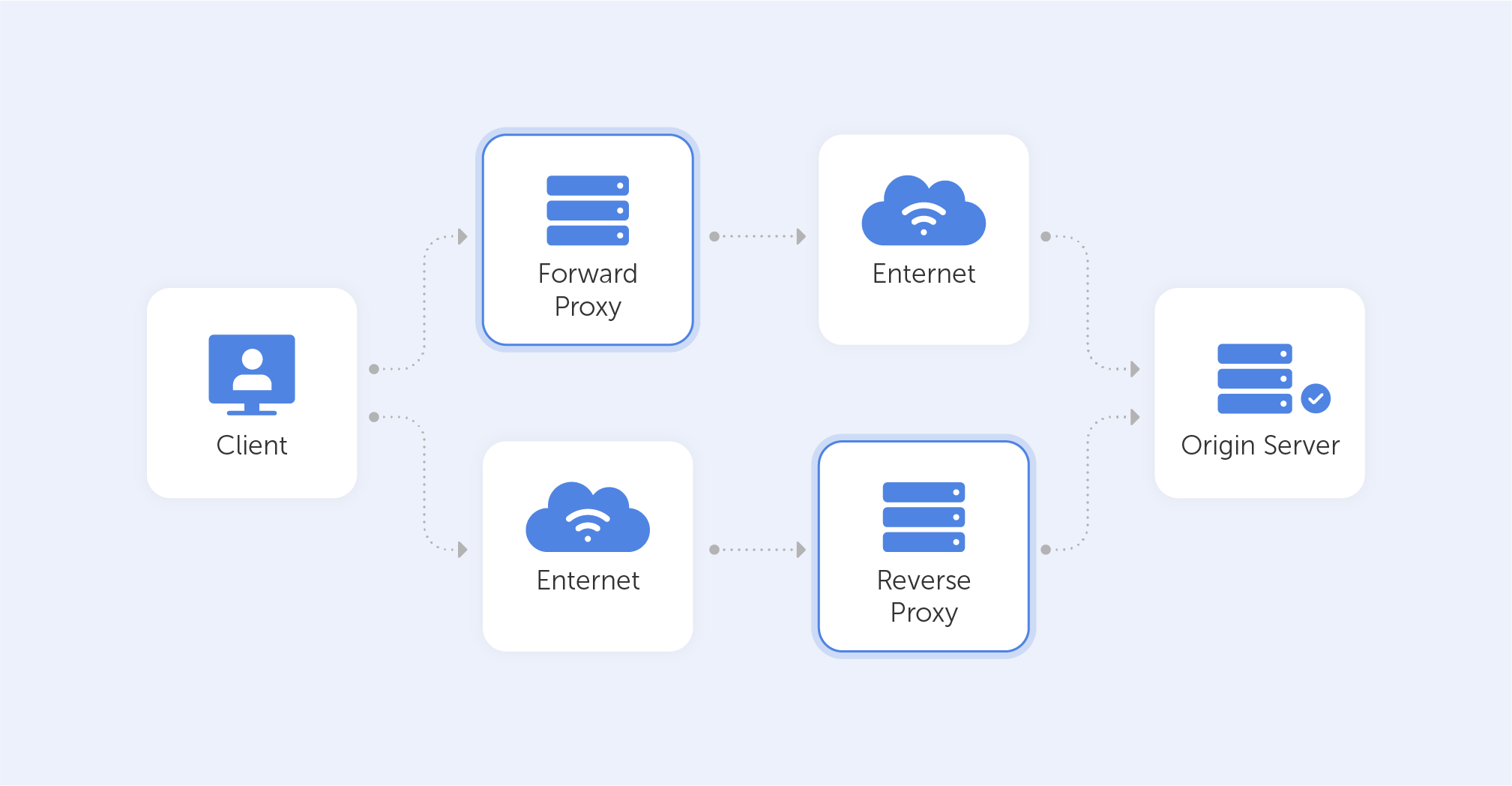
Importantly, there are two main types of proxies: Forward Proxies and Reverse Proxies. And even though the principle behind these two is similar, their use cases differ greatly.
Forward Proxies
In your day-to-day life, you’ll encounter forward proxies the most – these kinds of proxies sit between the client and the external network. They evaluate outbound requests and take action on them before relaying those requests to the external resources. Forward proxy servers allow the redirecting of traffic, meaning that if you have a proxy server installed within your local enterprise or on your home network, you’re able to effectively block choice websites. Maybe you don't want your kids to watch Netflix, or Dave from accounting keeps stalking his ex on Facebook when he should be writing up a report – in both cases, installing a proxy is a great solution. VPNs have a very similar function but feature encrypted traffic flows, if you’re on the market for such a tool, we recommend ExpressVPN. We’d also recommend steering clear of free proxies as there have been notable instances of traffic logging and sale on the black market.
Now, when using proxies, servers outside your network can’t understand who the client is, so by the same token, individuals or companies using forward proxies may access material that would otherwise be banned in their country or office. That’s exactly how the ‘GreatFirewall of China’ works, and it’s also how you’re able to stream a season on Netflix that would otherwise be banned in your country. This is why your office should restrict software downloads and access to in-browser forward proxies. Otherwise, Dave is just going to fight fire with fire.
So generally speaking, forward proxies are used to filter or unfilter Web content (depending on which side of the fence you sit).
Reverse proxies
Now that we’ve explained how a forward proxy works, disguising the client’s identity from the server, you can probably guess that the reverse proxy works vice-versa; the client doesn't know what exact server it is contacting. That may be used, for example, to help you rebalance the bandwidth between your service’s servers. That way, you can connect users to servers with the lowest load, or the smallest ping. Or, if your servers have a lot of static data - such as js scripts or HTML files on your website, they can be cached on a proxy server. Big social networks use reverse proxies to distribute the traffic among users' locations and corresponding data centers. The end-user, in most cases, remains oblivious to your internal process.
Some popular open-source reverse proxies are:
Still, most webmasters use the NGINX Reverse Proxy as it allows you to easily pass any request to a proxied server, configure buffers and choose the outgoing IP address.
The benefits of using a reverse proxy for your backend infrastructure are very straightforward:
- Load balancing – you’re able to set up your proxy server to choose the least loaded server each time a client makes a call. This will, of course, make the end-user experience incredibly smooth.
- Caching – as mentioned before, if your users perform identical calls to your server, you can store some data on the proxy server instead of loading your servers with heaps of requests (however, don't forget that caching on a proxy can sometimes be dangerous, so approach with caution).
- Isolating internal traffic – one of the best features indeed! You can run all your internal server architecture within a completely isolated DMZ. Also, it would remain a secret. All your port preferences, containers, virtual servers and physical servers shan’t be exposed to the outer world. This, of course, adds another layer of security to your infrastructure.
- Logging – you can log all internal network events on your reverse proxy. This means that if one of your servers returns an error – you can query and debug it on your proxy server. Moreover, it allows you to monitor the overall performance of your infrastructure easily from a single node.
- Canary Deployment – this means you can test some new features on only a selected percentage of users, You can also perform other AB tests. All of this allows you to significantly reduce risks when deploying updates to your service – your API calls are the same, the ports are the same, but your content is able to change dramatically.
- Scalability – if you need more servers, set them up and add them to the list of proxied servers. That's as simple as it gets.
There are plenty of scenarios and use cases in which having a reverse proxy can make all the difference when looking to improve the speed and security of your corporate network. By providing you with a point at which you can inspect traffic and route it to the appropriate server, or even one where you may transform the request entirely, a reverse proxy can be used to achieve a variety of different goals.
Using forward and reverse proxies allows you to significantly simplify your internal infrastructure. Not only are you bound to increase efficiency by keeping Dave off of Facebook, but you’re also adding another layer of security for both your employees and your servers. Logging will allow you to track your network usage and debug certain issues. In addition, caching definitely offers a smoother and more consistent experience to your end-users. So, throw your doubts to the wind and get involved. After all, most of the other successful services do it too.
What is a Proxy Server and How Does it Work?
Cryptography is both beautiful and terrifying. Perhaps a bit like your ex-wife. Despite this, it represents a vital component of day-to-day internet security; without it, our secrets kept in the digital world would be exposed to everyone, even your employer. I doubt you’d want information regarding your sexual preferences to be displayed to the regional sales manager while at an interview with Goldman Sachs, right?
Computers are designed to do exactly what we ask them to do. But sometimes there are certain things that we don’t want them to do, like expose your data through some kind of backdoor. This is where cryptography comes into play. It transforms useful data into something that can’t be understood without the proper credentials.
Let’s take a look at an example. Most internet services need to store their users’ password data on their own servers. But they can’t store the exact values that people input on their devices because, in the event of a data breach, malevolent intruders would effectively gain access to a simple spreadsheet of all usernames and passwords.
This is where ‘Hash’ and ‘Salt’ help us a lot. Throughout this article, we’re going to explain these two important encryption concepts through simple functions in Node.JS.
What is a ‘hash’?
A ‘hash’ literally means something that has been chopped and mixed, and originally was used to describe a kind of food. Now, chopping and mixing are exactly what the hash function does! You start with some data, you pass it through a hash function where it gets whisked and chopped, and then you watch it get transformed into a fixed-length value (which at first sight seems pretty meaningless). The important nuance here is that, contrary to cooking, an input always produces a corresponding output. For the purposes of cryptography, such a hash function should be easily computable and all values should be unique. It should work in a similar way to mashing potatoes – mashing is a one-way process; the raw potato may not be restored once it has been mashed. Indeed, the result of a hash function should be impenetrable to computer-led reverse engineering efforts.
These properties come in handy when you’re looking to store user passwords on a database – you don’t want anyone to know their real values.
Let’s implement a hash in Node.JS!
First, let’s import the createHash function from the built-in ‘crypto’ module:
const { createHash } = require ('crypto');Next, we ought to define the module that we’re naming as the ‘hash’ (which takes a string as the input, and returns a hash as the output):
function hash(input) {
return createHash();
}We also need to specify the hashing algorithm that we want to use. In our case, it will be SHA256. SHA stands for Secure Hash Algorithm and it returns a 256-bit digest (output). It is important to architect your code so it is easy to switch between algorithms because at some point in time they won’t be secure anymore. Remember, cryptography is always evolving.
function hash(input) {
return createHash('sha256');
}Once we call our hashing function, we may call ‘update’ with the input value and return the output by calling ‘digest’. We should also specify the format of the output (e.g. hex). In our case, we’ll go with Base64.
function hash(input) {
return createHash('sha256').update(input).digest('base64');
}Now that we have our hash function, we can provide some input, and console log the result.
let youShallNotPassPass = 'admin1234';
const hashRes1 = hash(youShallNotPassPass);
console.log(hashRes1)Here’s our baby hash:
rJaJ4ickJwheNbnT4+I+2IyzQ0gotDuG/AWWytTG4nA=
So, how can we use this long, convoluted string of numbers, letters, and symbols? Well, now it’s easy to compare two values while operating with only hashes.
let youShallNotPassPass = 'admin1234';
const hashRes1 = hash(youShallNotPassPass);
const hashRes2 = hash(youShallNotPassPass);
const isThereMatch = hashRes1 === hashRes2;
console.log(isThereMatch ? 'hashes match' : 'hashes do not match’)As long as hash values are unique object representations, they can be useful for object identification. For example, they might be used to iterate through objects in an array or find a specific one in the database.
But we have a problem. Hash functions are very predictable. On top of that, people don’t use strong passwords that often, so the hacker may just compare the hashes on a database with a precomputed spreadsheet of the most common passwords. If the values match – the password is compromised.
Because of this, it’s insufficient to just use a hash function to store unique ids on a password database.
And that’s where our second topic makes an entrance – Salt.
‘Salt’ is a bit like the mineral salt that you would add to a batch of mashed potatoes – the taste will definitely depend on the amount and type of salt used. This is exactly what salt in cryptography is – random data that is used as an additional input to a hash function. Its use makes it much harder to guess what exact data stands behind a certain hash.
So, let’s salt our hash function!
First, we ought to import ‘Scrypt' and ‘RandomBytes’ from the ‘crypto’ module:
const { scryptSync, randomBytes } = require('crypto');Next, let’s implement signup and login functions that take ‘nickname’ and ‘password’ as their inputs:
function signup(nickname, password) { }
function login(nickname, password) { }When the user signs up, we will generate a salt, which is a random Base64 string:
const salt = randomBytes(16).toString('base64');And now, we hash the password with a 'pinch' of salt and a key length, which is usually 64:
const hashedPassword = scryptSync(password, salt, 64).toString('base64');We use ‘Scrypt’ because it’s designed to be expensive computationally and memory-wise in order to make brute-force attacks unrewarding. It’s also used as proof of work in cryptocurrency mining.
Now that we have hashed the password, we need to store the accompanying salt in our database. We can do this by appending it to the hashed password with a semicolon as a separator:
const user = { nickname, password: salt + ':' + hashedPassword}Here’s our final signup function:
function signup(nickname, password) {
const salt = randomBytes(16).toString('base64');
const hashedPassword = scryptSync(password, salt, 64).toString('base64');
const user = { nickname, password: salt + ':' + hashedPassword};
users.push(user);
return user;
}Now let’s create our login function. When the user wants to log in, we can grab the salt from our database to recreate the original hash:
const user = users.find(v => v.nickname === nickname);
const [salt, key] = user.password.split(':');
const hash = scryptSync(password, salt, 64);After that, we simply check whether the result matches the hash in our database. If it does, the login is successful:
const match = hash === key;
return match;Here is the complete login function:
function login(nickname, password) {
const user = users.find(v => v.nickname === nickname);
const [salt, key] = user.password.split(':');
const hash = scryptSync(password, salt, 64).toString('base64');
const match = hash === key;
return match;
}Let’s do some testing:
//We register the user:
const user = signup('Amy', '1234');
//We try to login with the wrong pass:
let isSuccess = login('Amy', '12345');
console.log(isSuccess ? 'Login success' : 'Wrong password!')
//Wrong password!
//We try to login with the correct pass:
isSuccess = login('Amy', '1234')
console.log(isSuccess ? 'Login success' : 'Wrong password!')
//Login successOur example, hopefully, has provided you with a very simplified explanation of the signup and login process. It’s important to note that our code is not protected against timing attacks and it doesn’t use PKI infrastructure to check hashes, so there are plenty of vulnerabilities for hackers to exploit.
Cryptography itself can be described as the constant war between hackers and cryptographic engineers. Or, that familiar legal battle with your ex-wife over her maintenance payments. After all, what works today may not work tomorrow. A proof of MD5 hash algorithm vulnerability is a very good example.
So if your task is to ensure your users’ data privacy, be ready to constantly update your functions to counteract the recent ‘breakthroughs’.
What is password hashing and salting?
Let's imagine that you decided to google ‘best sauces for Wagyu steak’. You went through several web pages, and then on page two of the search results, you get this notification from your Chrome browser:
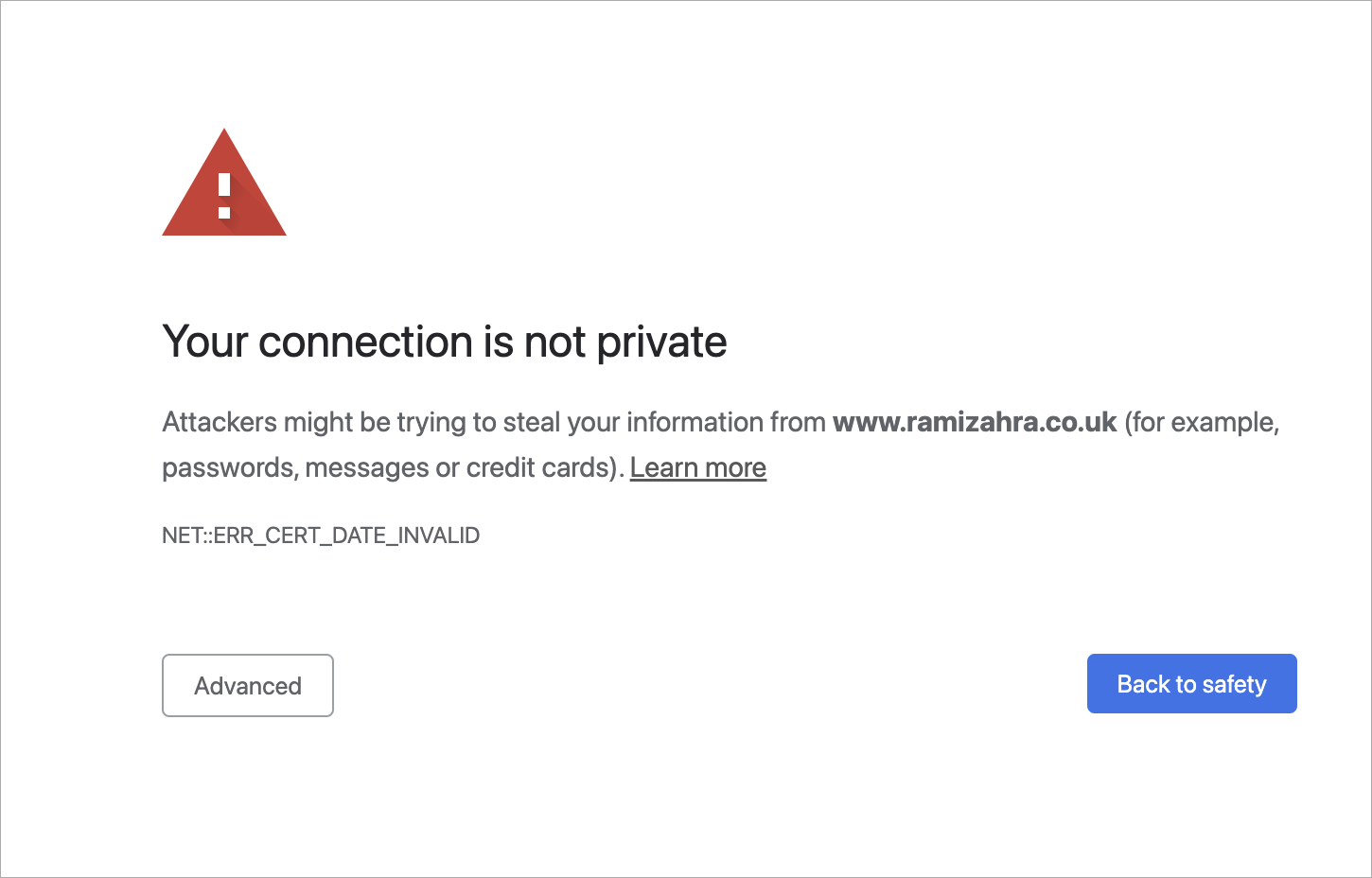
Something went wrong, that's for sure. What happened? Should you proceed to the page without a private connection?
An IT expert would surely reply:
The error that you got here was probably because of an SSL/TLS handshake failure.
SSL? TLS?? Acronyms you’ve no doubt heard before, but ones that nevertheless evoke a dreary sense of confusion in the untrained mind. In this article, we’ll try to explain what SSL/TLS is, how it works and at the very least, you’ll understand what that lock icon on the address bar is.
Where did TLS originate?
TLS stands for Transport Layer Security, and it is right now the most common kind of Web PKI. It’s used not only to encrypt internet browsing but also for end-to-end connection (video calling, messaging, gaming, etc.).
As for now, we expect almost any kind of connection on the internet to be encrypted, and if something is encrypted, we get an alert similar to that seen in figure A. But that wasn't always the case. If you go back to the mid-90s – very little on the internet was encrypted. Maybe that was because fewer people were using the internet back then, or maybe it was because there weren’t credit-card details flying all over the place.
The history of TLS starts with Netscape. In 1994, it developed Secure Socket Layer 1 – the grandfather of modern TLS. Technically, it fits between TCP and HTTP as a security layer. While version 1 was used only internally and was full of bugs, very quickly, they fixed all the issues and released SSL 2. Then, Netscape patented it in 1995 with a view to stopping other people patenting it so they could release it for free. This was a very odd yet generous move, considering what the real-life patent practice was at that time.
In 1995, the world was introduced to Internet Explorer, a browser that used a rival technology called PCT (Private Communications Technology), which was very similar to SSL. But as with any rivalry – there could only be one winner. In November 1996, SSL 3 was released, which, of course, was an improvement on SSL 2. Right after that, the Internet Engineering Task Force created the Transport Layer Security Working Group to decide what the new standard for internet encryption would be. It was subsequently renamed from SSL to TLS (as far as we know, this was because Microsoft didn't want Netscape to have dibs on the name). It actually took three years for the group to release TLS 1. It was so similar to SSL 3 that people began to name it SSL 3.1. But over time, through updates, the security level rose massively; bugs were terminated, ciphers were improved, protocols were updated etc.
But, how does it all actually work?
TLS is a PKI protocol that exists between two parties. They effectively have to agree on certain things to identify each other as trustworthy. This process of identification is called a 'handshake'.
Let’s take a look at a TLS 1.2 handshake, as an example.
First, let's load any webpage, then, depending on your browser, press the lock icon near the web address text field. You’ll be shown certificate info and somewhere between the lines you'll find a string like this:
This is called a Cipher Suite. It’s a string-like representation of our 'handshake' recipe.
So, let’s go through some of the things shown here:
- First, we have ECDHE (Elliptic-curve Diffie–Hellman), which is a key agreement protocol that allows two parties, each having an elliptic-curve public–private key pair, to establish a shared secret over an insecure channel. In layman’s terms, this is known as key exchange;
- The RSA is our Public Key authentication mechanism (remember, we need a Public Key for any PKI);
- AES256 refers to the cipher that we’re going to use (AES) and its' key size (256);
- Lastly, SHA384 is effectively a building block that is used to perform hash functions.
Now, the trick is to exchange all that data in just several messages via our 'handshake'.
What exactly happens when we go to a new web page?
After we establish a TCP (Transmission Control Protocol) connection, we start our handshake. As always on the web, the user (Client) is requesting data from the Server – so he sends a 'Client Hello' message, which contains a bunch of data including:
- The max TLS version that this Client can support so that both parties are able to 'speak the same language;
- A random number to protect from replay attacks;
- List of the cipher suites that the Client supports.
Assuming the Server is live, it responds with 'Server Hello', containing the Cipher Suite and TLS version it chose to connect with the Client + a random number. If the server can't choose a Suite or TLS version due to version incompatibility – it sends back a TLS Alert with a handshake failure. At this point, both the User and the Server know the communication protocol.
Keep in mind that the server is sending a Public key and a Certificate containing an RSA key. It’s important to know that the Certificate has an expiration date. You’ll understand why by the end of the article.
On top of that, the Server is sending a Server Key Exchange Message containing parameters for ECDHE with a public value. Very importantly, this Exchange Message also contains a digital signature (all previous messages are summarized using a hash function and signed using the private key of the Server). This signature is crucial because it provides proof that the Server is who they say they are.
When the Server is done transmitting all the above-mentioned messages, it sends a 'Server Hello Done' message. In Layman’s terms, that’s an ‘I’m done for the day, I’ll see you at the pub’ kind of message.
The Client, on the other hand, will look at the Certificate and verify it. After that, it will verify the signature using the Certificate (you can't have one without the other). If all goes well, the Client is assured of the Server’s authenticity and sends a Client Key Exchange Message. This message doesn't contain a Certificate but does contain a Pre-master Secret. It is then combined with the random numbers that were generated during the ‘Hello’ messages to produce a Master Secret. The Master Secret is going to be used for encryption at the next step.
It may seem very complicated now, but we’re almost done!
The next stage involves the Client sending the ‘Change Cipher Spec’ message, which basically says "I’ve got everything, so I can begin encryption – the next message I'll send you is going to be encrypted with parameters and keys".
After that, the Client proceeds to send the ‘Finished’ message containing a summary of all the messages so far encrypted. This helps to ensure that nobody fiddled with the messages; if the Server can't decrypt the message, it leaves the 'conversation'.
The Server will reply in the same way – with a Change Cipher Spec and a Finished message.
Handshaking is now done, parties can exchange HTTP requests/responses and load data. By the way, the only difference between HTTP and HTTPS is that the last one is secure – that's what the 'S' stands for there.
As you can see, it's incredibly difficult to crack this system open. However, that's exactly what we need to ensure security. Moreover, those two round trips that the data travels take no time at all, which is great; nobody wants their GitHub to take a month and a half to load up. By the way, the more advanced TLS 1.3 does all that in just one round trip!
Your connection is not private
When something goes wrong with TLS, you’ll see the warning that we demonstrated at the very beginning of this article. Usually, those are issues associated with the Certificate and its expiration date. That’s why your internet will refuse to work if you’ve messed around with the time and date settings on your device. But, if everything with the date and time is in check – never proceed to a website that triggers this warning, because most likely, between you and the server, somebody is parsing your private data.
What is Transport Layer Security (TLS) & how does it work?
Let’s imagine that somehow you’re in the driver’s seat of a start-up, and a successful one too. You’ve successfully passed several investment rounds and you’re well on your way to success. Now, big resources lead to big data and with big data, there’s a lot of responsibility. Managing data in such a company is a struggle, especially considering that data is usually structured in an access hierarchy – Excel tables and Google Docs just don’t cut the cake anymore. Instead, the company yearns for a protocol well equipped to manage data. The company yearns for LDAP.
What is LDAP?
The story of LDAP starts at the University of Michigan in the early 1990s when a graduate student, Tim Howes, was tasked with creating a campus-wide directory using the X.500 computer networking standard. Unfortunately, accessing X.500 records was impossible without a dedicated server. Additionally, there was no such thing as a ‘client app’. As a result, Howes co-created DIXIE, a directory client for X.500. This work set the foundations for LDAP, a standards-based version of DIXIE for both clients and servers – an acronym for the Lightweight Directory Access Protocol.
It was designed to maintain a data hierarchy for small bits of information. Unlike ‘Finder’ on your Mac, or ‘Windows Explorer’ on your PC, the ‘files’ inside the directory tree, although small, are contained in a very hierarchical order – exactly what you need to organize, for example, your HR structure, or when accessing a file. Compared to good old Excel, it is not a program, but rather a protocol. Essentially, a set of tools that allow users to find the information that they need very quickly.
Importantly, this protocol answers three key questions regarding data management:
— Who? Users must authenticate themselves in order to access directories.
— How? A special language is used that provides for query or data manipulations.
— Where? Data is stored and organized in a proper manner.
Let’s now go through these key questions in greater detail.
Who?
It’s bad taste to provide internal data to any old Joe. That’s why LDAP users cannot access information without first proving their identity.
LDAP authentication involves verifying provided usernames and passwords by connecting with a directory service that uses the LDAP protocol. All this data is stored in what is referred to as a core user. This is a lot like logging into Facebook, where you’re only able to access a user’s feed and photos if they’ve accepted your friend request, or if their profile has been set to public.
Some companies that require advanced security use a Simple Authentication and Security Layer (SASL), for example, Kerberos, for the authentication process.
In addition, to ensure the maximum safety of LDAP messages, as soon as data is accessed via devices outside the company’s walls, Transport Layer Security (TLS) may be used.
How?
The main task of a data management system is to provide “many things to many users”.
Rather than creating a complex system for each type of information service, LDAP provides a handful of common APIs (LDAP commands) to do this. Supporting applications, of course, have to be written to use these APIs properly. Still, the LDAP provides the basic service of locating information and can thus be used to store information for other system services, such as DNS, DHCP, etc.
Basic LDAP commands
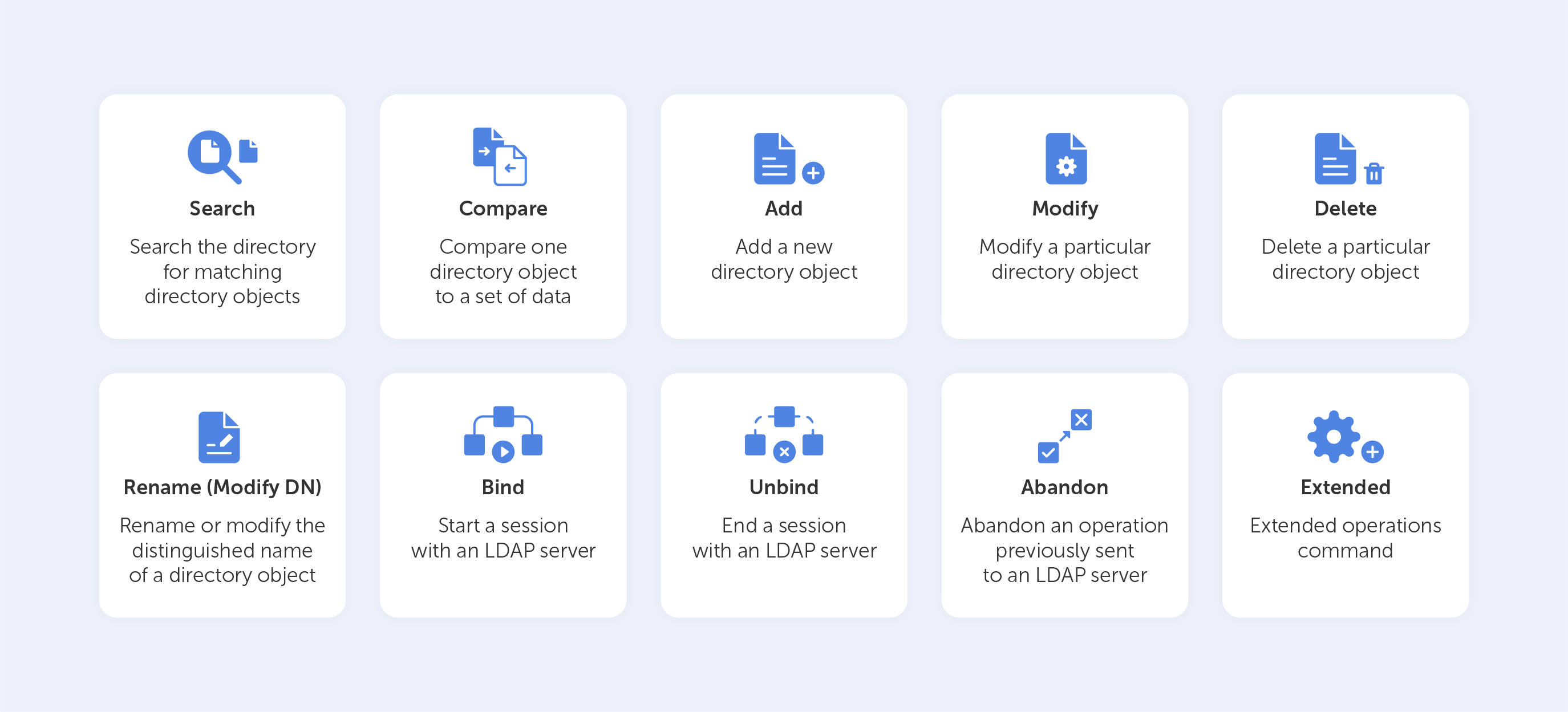
Let’s look at the ‘Search’ LDAP command as an example, if you’d like to know which group a particular user is a part of, you might need to input something like this:
(&(objectClass=user)(sAMAccountName=BradleyC)
(memberof=CN=Perohouse,OU=Users,DC=perohouse,DC=com))
Isn’t it beautiful? Not quite as simple as performing a Google search, that’s for sure. So, your employees will perform all their directory services tasks through a point-and-click management interface like Varonis DatAdvantage.
All those interfaces may vary depending on their configuration, which is why new employees should be trained to use them, even if they’ve used LDAP before.
Where?
As we mentioned before, LDAP has the structure of a tree of information. Starting with the roots, it contains hierarchical nodes relating to a variety of data, by which the query may then be answered.
The root node of the tree doesn't really exist and can't be accessed directly. There is a special entry called the root directory specific entry, or rootDSE, that contains a description of the whole tree, its layout, and its contents. But, this really isn't the root of the tree itself. Each entry contains a set of properties, or attributes, in which data values are stored.
The tree itself is called the directory information tree (DIT). Branches of this tree contain all the data on the LDAP server. Every branch leads to a leaf in the end – a data entry, or directory service entry (DSE). These entries contain actual records that describe objects such as users, computers, settings, etc.
For example, such a tree for your company could start with the description of a position held, starting with you at the top as the director, finishing at the bottom with Joe Bloggs, the intern.
Each position would be tied to a person with a set of attributes, complete with links to subordinates. The attributes for a person may include their name, surname, phone number, email, in addition to their responsibilities. Each attribute would have a value inside, like ‘Joe’ for name and ‘Bloggs’ for surname.
The actual data contents may vary, as they totally depend on use. For example, you could have data issuing rights to certain people regarding the coffee machine. So, no Frappuccino for our intern Joe.
Sure, you can add more sophisticated data regarding each individual – their personal family trees, or even voice samples for instance, but typically, the LDAP would just point to the place where such data can be found.
Is it worth it?
LDAP is able to aggregate information from different sources, making it easier for an enterprise to manage information. But as with any type of data organization, the biggest difficulty is creating a proper design for your tree. There is always trial and error involved while building a directory for a specific corporate structure. Sometimes this process is so difficult that it even results in the reorganization of the company itself in favour of the hierarchical model. Despite this, for almost thirty years, the LDAP has held its title as the most efficient solution for the organization of corporate data.
What is LDAP and how does LDAP authentication work?
Imagine you’re a system administrator at Home Depot. Just as you’re about to head home, you notice that your network has just authorized the connection of a new air-conditioner. Nothing too peculiar, right? The next morning, you wake up to find that terabytes of data including logins, passwords and customer credit card information have been transferred to hackers. Well, that’s exactly what happened in 2014, when a group of hackers, under the guise of an unassuming HVAC system, landed an attack that cost Home Depot over $17.5 million dollars, all over an incorrectly configured PKI. In this article, we’ll be conducting a crash course in PKI management.
So, what’s a PKI?
‘Public key infrastructure’ is a term that relates to a set of measures and policies that allow one to deploy and manage one of the most common forms of online encryption – public-key encryption. Apart from being a key-keeper for your browser, the PKI also secures a variety of different infrastructures, including internal communication within organizations, Internet of Things (IoT), peer to peer connection, and so on. There are two main types of PKIs:
• The Web PKI, also known as the “Internet PKI”, has been defined by RFC 5280 and refined by the CA/Browser Forum. It works by default with browsers and pretty much everything else that uses TLS (you probably use it every day).
• An Internal PKI – is the one you run for your own needs. We’re talking about encrypted local networks, data containers, enterprise IT applications or corporate endpoints like laptops and phones. Generally speaking, it can be used for anything that you want to identify.
At its core, PKI has a public cryptographic key that is used not to encrypt your data, but rather to authenticate the identities of the communicating parties. It’s like the bouncer outside an up-market club in Mayfair – you’re not getting in if you’re not on the list. However, without this ‘bouncer’, the concept of trustworthy online communication would be thrown to the wind.
So, how does it work?
PKI is built around two main concepts – keys and certificates. As with an Enigma machine, where the machine’s settings are used to encrypt a message (or establish a secure protocol), a key within a PKI is a long string of bits used to encrypt or decrypt encoded data. The main difference between the Enigma machine and a PKI is that with the latter, you have to somehow let your recipient know the settings used to encode the encrypted message.
The PKI gets its name because each party in a secured connection has two keys: public and private. A generic cipher protocol on the other hand, usually only uses a private one.
The public key is known to everyone and is used throughout the network to encode data, but the data cannot be accessed without a private key, which is used for decoding. These two keys are bound by complex mathematical functions which are difficult to reverse-engineer or crack by brute force. By the way, this principle is an epitome of asymmetrical cryptography.
So, this is how data is encrypted within a public key infrastructure. But let’s not forget that identity verification is just as important when dealing with PKIs – that’s where certificates come into play.
Digital Identity
PKI certificates are most commonly seen as digital passports containing lots of assigned data. One of the most important pieces of information in such a certificate relates to the public key: the certificate is the mechanism by which that key is shared – just like your Taxpayer Identification Number (TIN) or driver’s license, for instance.
But it’s not really valid unless it has been issued by some kind of entrusted authority. In our case, this is the certificate authority (CA). Here, there is an attestation from a trusted source that the entity is who they claim to be.
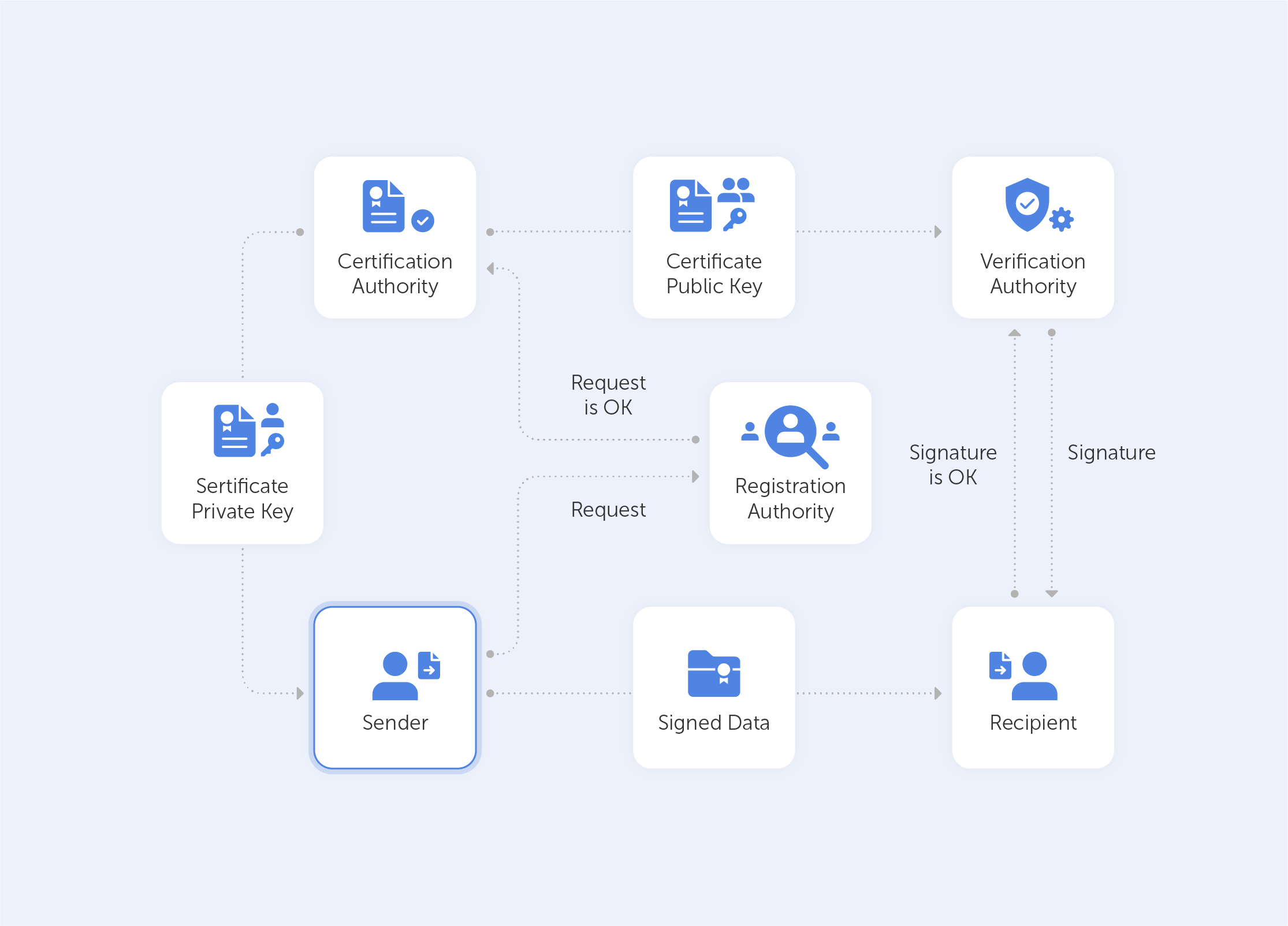
With this in mind, it becomes very easy to grasp what the PKI consists of:
• A certificate authority, which issues digital certificates, signs them with its public key and stores them in a repository for reference;
• A registration authority, which verifies the identities of those requesting digital certificates. A CA can act as its registration authority or can use a third party to do so;
• A certificate database that stores both the certificates, their metadata and, most importantly, their expiration dates;
• A certificate policy outlining the PKI's procedures (this is basically a set of instructions that allows others to judge how trustworthy a PKI is).
What is a PKI used for?
A PKI is great for securing web traffic – data flowing through the open internet can be easily intercepted and read if it isn't encrypted. Moreover, it can be difficult to trust a sender’s identity if there isn’t some kind of verification procedure in place.
But even though SSL/TLS certificates (that secure browsing activities) may demonstrate the most widespread implementation of PKI, the list doesn’t end there. PKI can also be used for:
• Digital signatures on software;
• Restricted access to enterprise intranets and VPNs;
• Password-free Wifi access based on device ownership;
• Email and data encryption procedures.
PKI use is taking off exponentially; even a microwave can connect to Instagram nowadays. This emerging world of IoT devices brings us new challenges and even devices seemingly existing in closed environments now require security. Taking the ‘evil air conditioner’ that we spoke about in the introduction as an example – gone are the days where we can take a piece of kit for face value. Some of the most compelling PKI use cases today centre around IoT. Auto manufacturers and medical device manufacturers are two prime examples of industries currently introducing PKI for IoT devices. Edison’s Electronic Health Check-up System would be a very good example here, but we’ll save that for a future deep-dive.
Is PKI a cure-all?
As with any technology – execution is sometimes more important than the design itself. A recent study by the Ponemon Institute surveyed nearly 603 IT and security professionals across 14 industries to understand the current state of PKI and digital certificate management practices. This study revealed widespread gaps and challenges, for example:
• 73% of security professionals admit that digital certificates still cause unplanned downtime and application outages;
• 71% of security professionals state that migration to the cloud demands significant changes to their PKI practices;
• 76% of security professionals say that failure to secure keys and certificates undermines the trust their organization relies upon to operate.
The biggest issue, however, is that most organizations lack the resources to support PKI. Moreover, only 38% of respondents claim they have the staff to properly maintain PKI. So for most organisations PKI maintenance becomes a burden rather than a cure-all.
To sum up, PKI is a silent guard that secures the privacy of ordinary online content consumers. However, in the hands of true professionals, it becomes a power tool that creates an encryption infrastructure that is almost infinitely scalable. It lives in your browser, your phone, your wifi access point, throughout the web and beyond. Most importantly, however, a correctly-configured PKI is the distance between your business and an imposter air conditioner that wants your hard-earned cash.